
Section 1: Pre-Neural Machine Translation
机器翻译(MT)是将一个句子$x$从一种语言(源语言)转换为另一种语言(目标语言)的句子$y$的任务。

1990s-2010s: Statistical Machine Translation
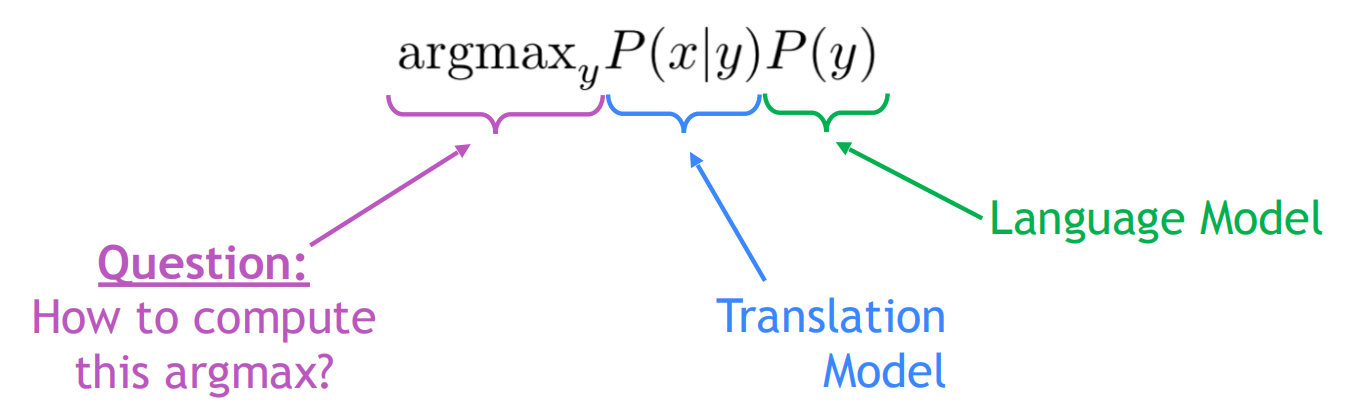
统计机器翻译的核心是基于概率模型的。加入我们要将法语翻译成英语,我们需要找到最好的英语句子$y$,对于给定的法语句子$x$,求:
通过贝叶斯规则可以将其拆解为两个部分分别进行学习
其中$P(x|y)$专注于翻译模型,翻译好局部的短语或者单词,使得翻译更加准确无误,它可以并行的从数据中进行学习。$P(y)$专注于语言模型,用来学习整个句子$y$的概率,使得翻译出来的句子更加的流利通顺,它需要从自身语言的数据中进行学习
What is alignment?
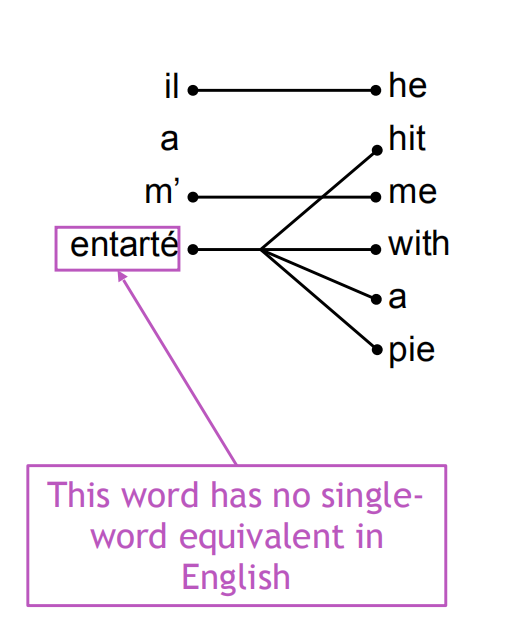
SMT进一步把$P(x|y)$分解成$P(x,a|y)$,其中$a$表示一个对齐alignment,可以认为是两种语言之间单词和单词或短语和短语的一个对齐关系。
- 有些词是没有对应词的
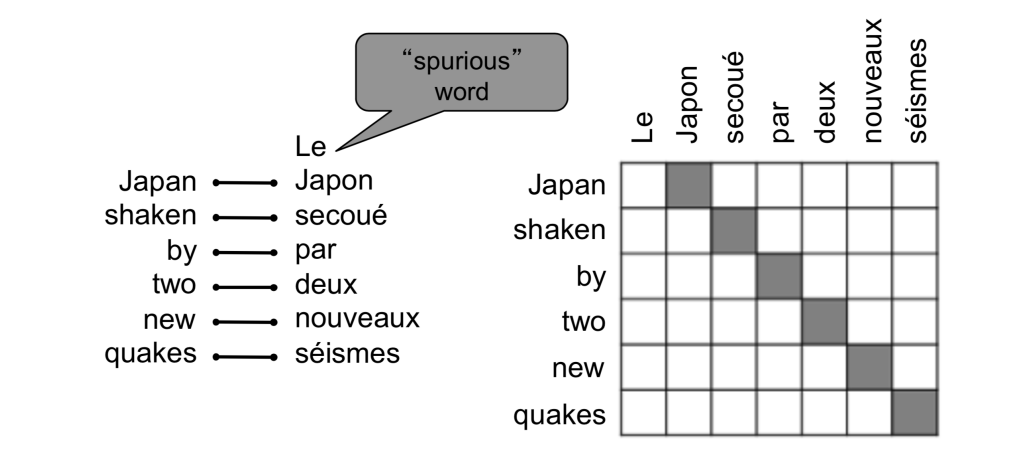
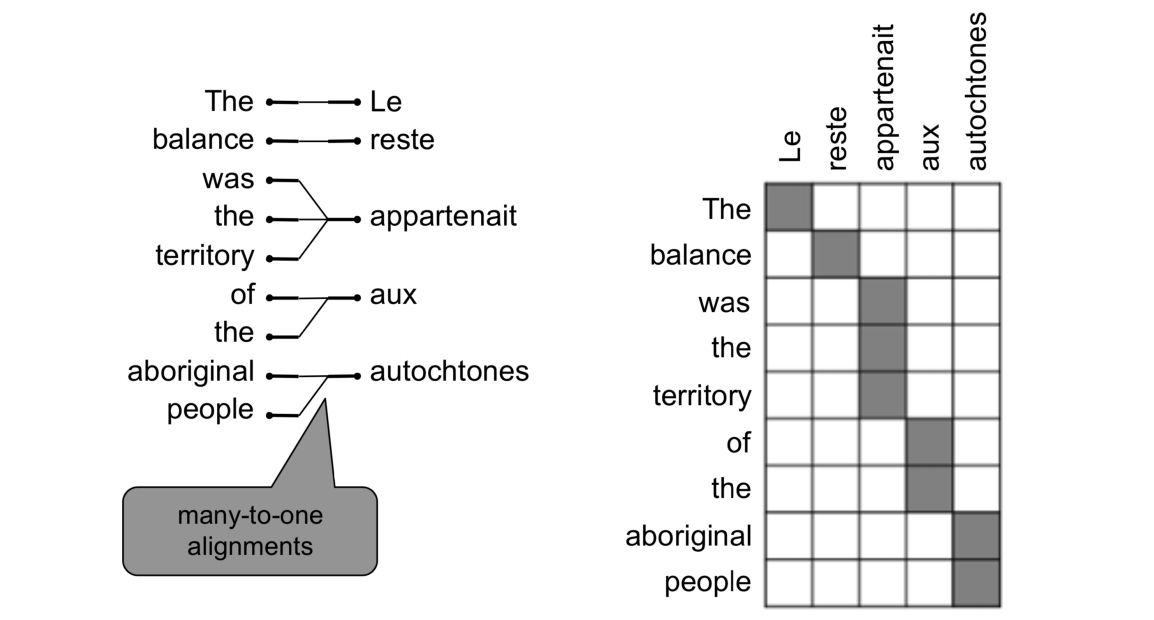
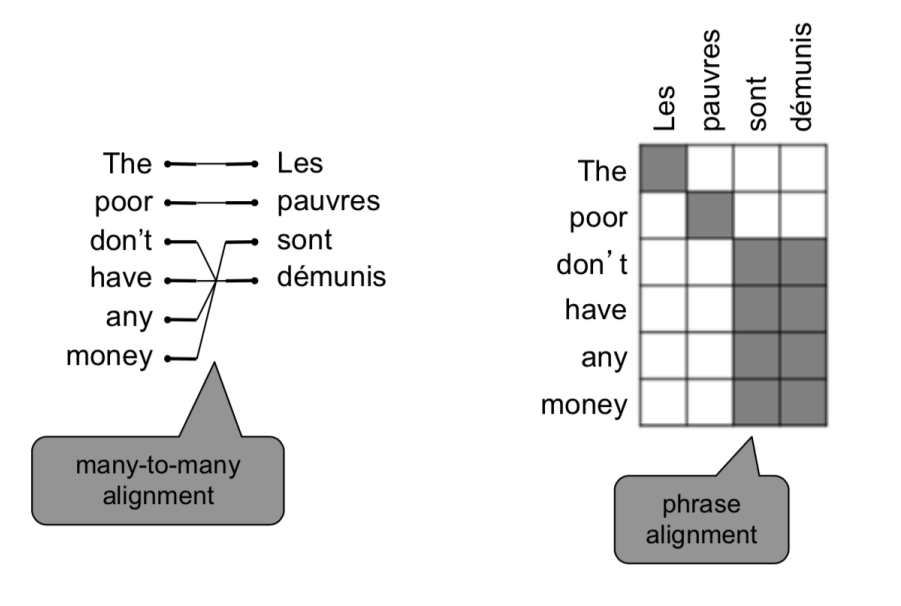
- 对齐本身就很复杂,存在1对1,多对1,1对多,多对多等情况
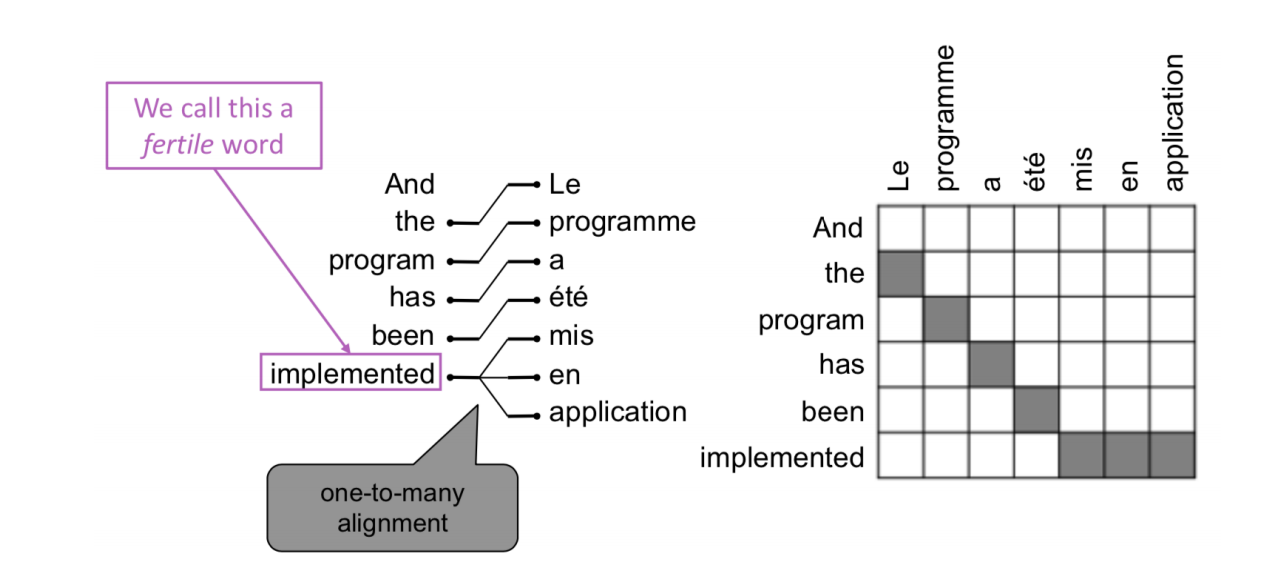
- 有些词很丰富
Decoding for SMT
如何计算$argmax_y$?
- 我们可以列举所有可能的$y$并计算概率?这样的话代价太大
- 使用启发式搜索算法搜索最佳翻译,丢弃概率过低的假设
- 这个过程称为解码
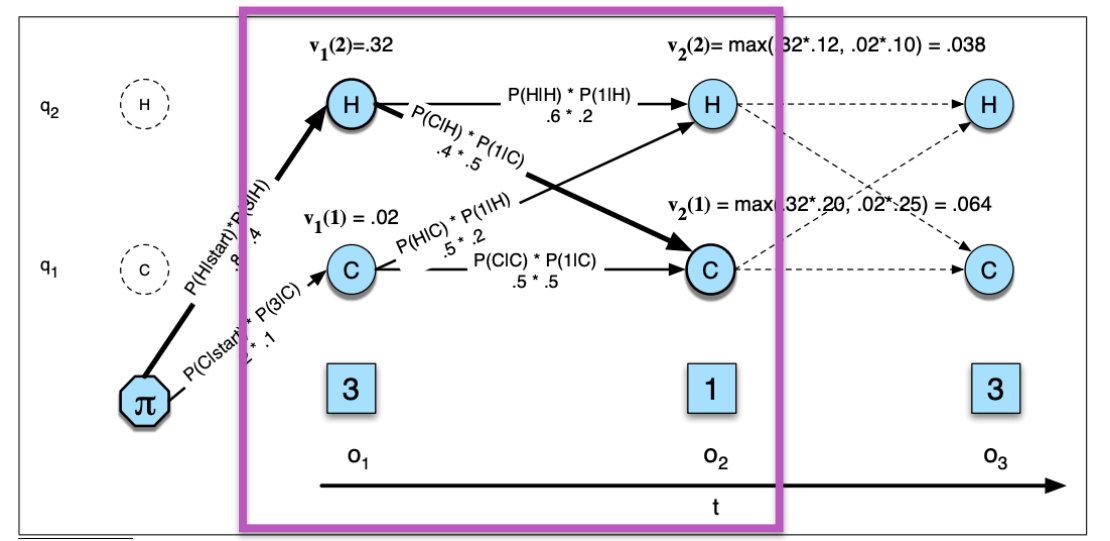
解码可以使用Viterbi解码法,假设模型为独立的,则有:
SMT是一个巨大的研究领域,有很多的子模块,需要很多的人工干预和特征工程。
Section 2: Neural Machine Translation
What is Neural Machine Translation?
- 神经机器翻译是利用单个神经网络进行机器翻译的一种方法
- 神经网络架构称为sequence-to-sequence(又名seq2seq),它包含两个RNNs
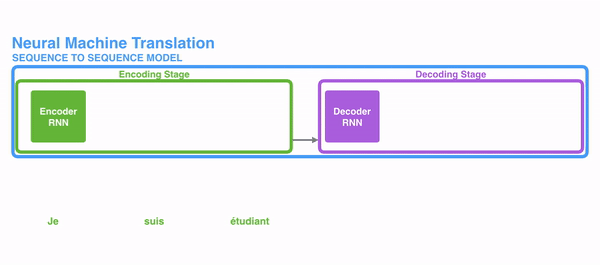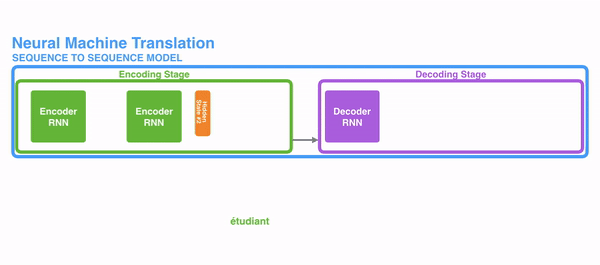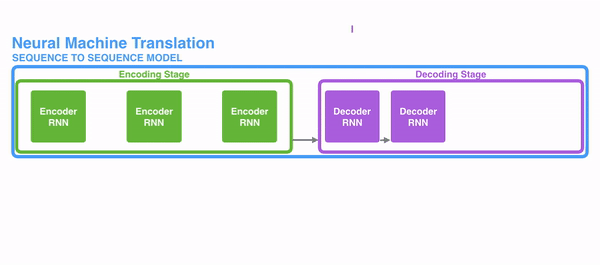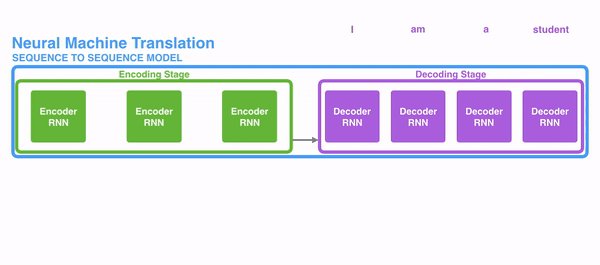
Neural Machine Translation(NMT)
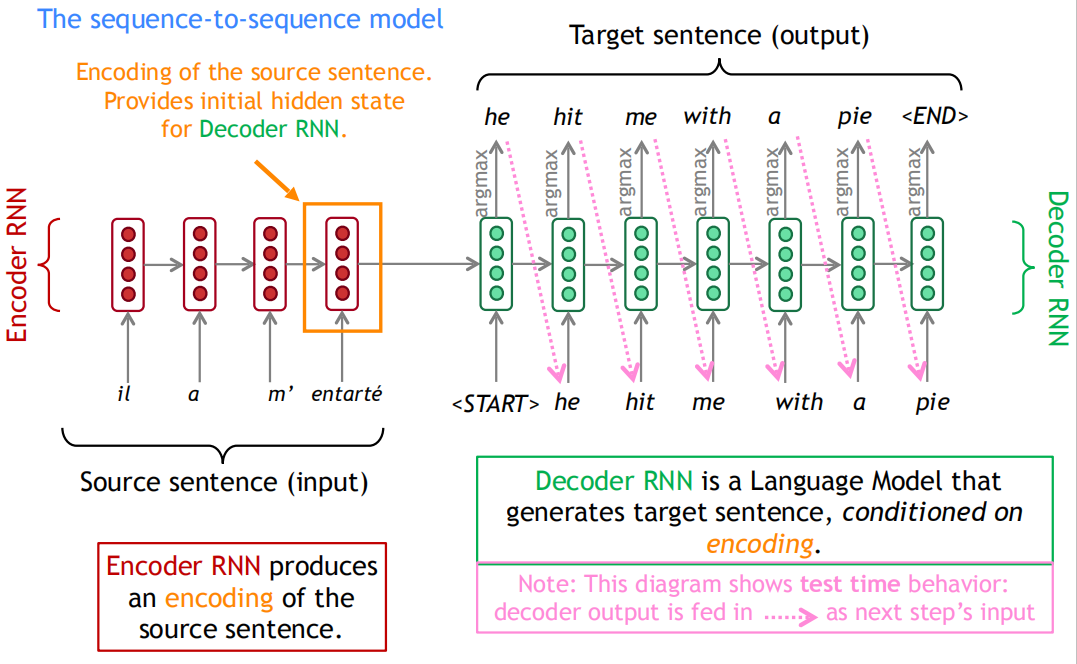
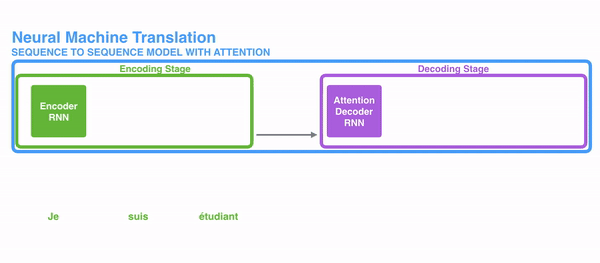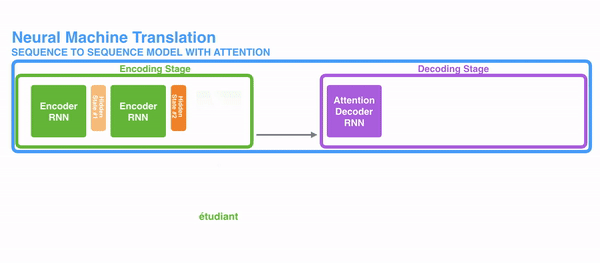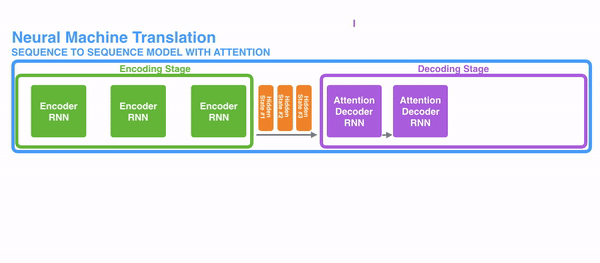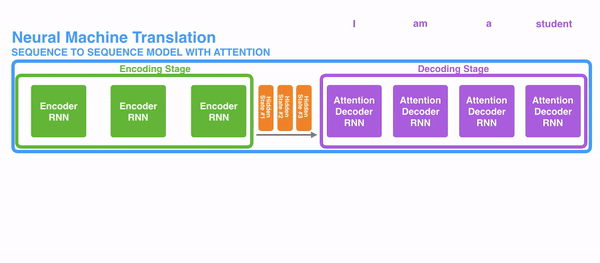
Seq2seq两个RNN组成,左边的红色部分称为Encoder RNN,它负责对源语言进行编码,右边的绿色部分称为Decoder RNN,它负责对目标语言进行解码。
Encoder RNN可以是任意一个RNN,比如朴素RNN、LSTM或者GRU。Encoder RNN负责对源语言进行编码,学习源语言的隐含特征。Encoder RNN的最后一个神经元的隐状态作为Decoder RNN的初始隐状态。
Decoder RNN是一个条件语言模型,一方面它是一个语言模型,即用来生成目标语言,另一方面,它的初始隐状态是基于Encoder RNN的输出,所以称Decoder RNN是条件语言模型。Decoder RNN在预测的时候,需要把上一个神经元的输出作为下一个神经元的输入,不断的预测下一个词,直到预测输出了结束标志符END而停止预测。Encoder RNN的输入是源语言的word embeding,Decoder RNN的输入是目标语言的word embeding。
Seq2seq不仅仅对MT有用,许多NLP任务可以按照顺序进行表达:
- 摘要(长文本$\rightarrow$短文本)
- 对话(前一句话$\rightarrow$下一句话)
- 解析(输入文本$\rightarrow$输出解析为序列)
- 代码生成(自然语言$\rightarrow$Python代码)
Seq2seq作为一个条件语言模型,它直接计算$P(y|x)$,在生成$y$的过程中,始终有$x$作为条件
上式中最后一项为,给定到目前为止的目标词和源句$x$,下一个目标词的概率
Training a Neural Machine Translation system
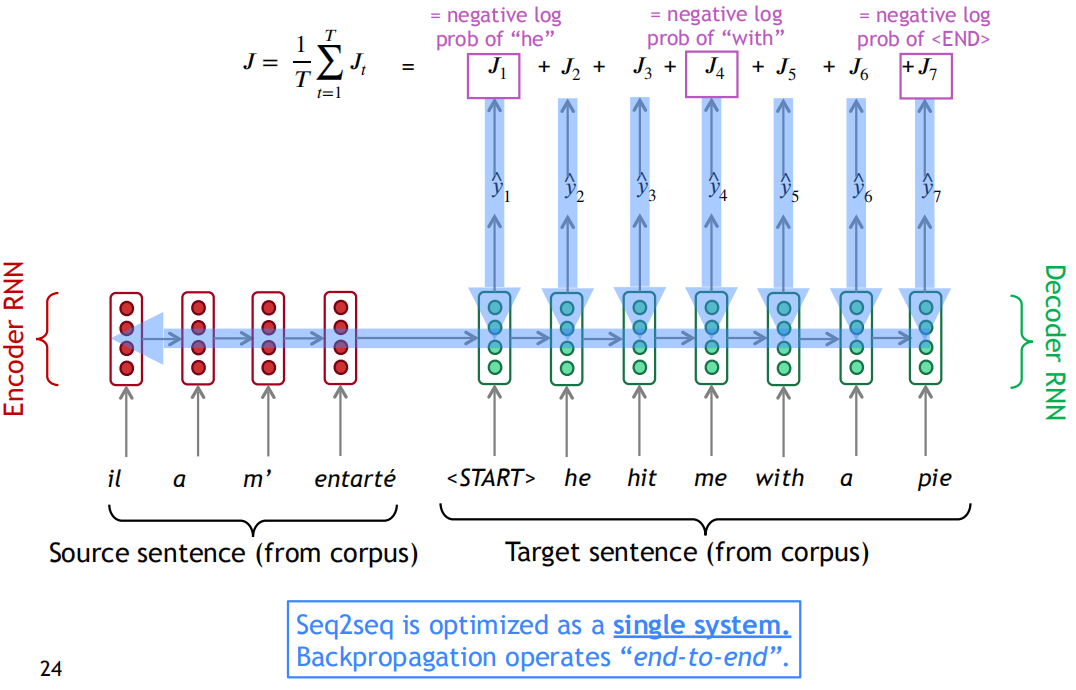
seq2seq的训练过程如下图所示,训练的时候,我们同时需要源语言和翻译好的目标语言,分别作为Encoder RNN和Deocder RNN的输入。Decoder RNN在训练阶段,每一个时刻的输入是提供的正确翻译词,输出是预测的下一个时刻词的概率分布,比如在$t=4$时刻,预测输出是$\hat{y}_4$
,而正确答案是”with”,根据交叉熵损失函数,$J_4=-logP(“with”)$,总的损失函数就是所有时刻的损失均值。
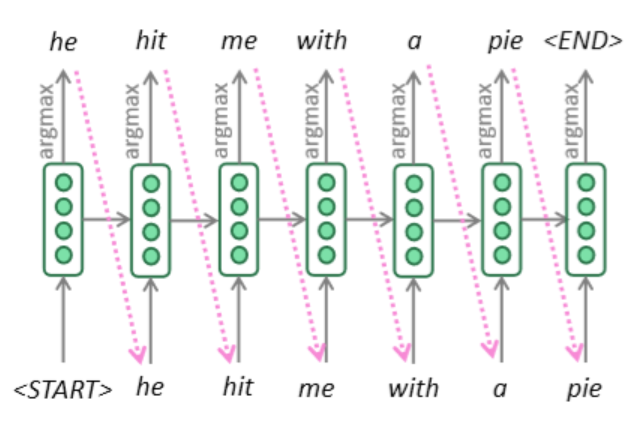
seq2seq的预测过程,实际上是一个贪心的预测过程,即在Decoder RNN的每一步都贪心选择概率$\hat{y}_t$最大的那个词。如下图,贪心只能保证每一步最优,不能保证全局最优,贪心算法没有办法回溯,但是如果每个时刻都穷举所有可能的话,时间复杂度为$O(V^T)$,太高了
Beam search decoding
Beam search搜索策略是贪心策略和穷举策略的一个折中方案,它在预测的每一步,都保留Top-k高概率的词,作为下一个时间步的输入。k称为beam size,k越大,得到更好结果的可能性更大,但计算消耗也越大。这里的Top-k高概率不仅仅指当前时刻$\hat{y}_t$
的最高概率,而是截止目前这条路径上的累计概率之和

Beam search decoding: example
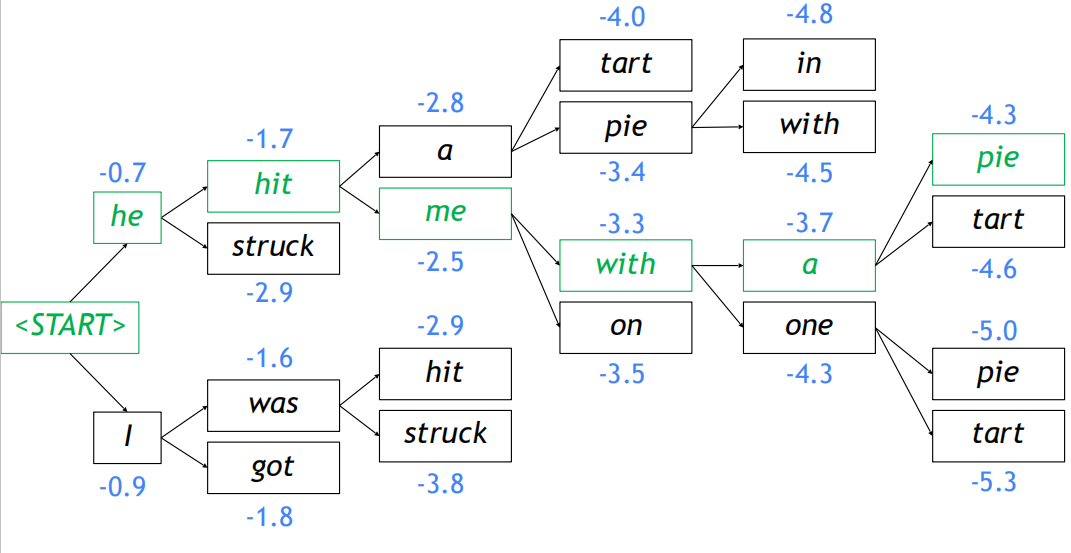
假设Beam size: $k = 2$,蓝色的数字是$score(y_1…,y_t)=\sum^t_{i=1}logP_{LM}(y_i|y_1,…,y_{i-1},x)$的结果:
- 第一步:计算每个分支下下一个单词的概率分布
- 第二步:取每个分支的前2个单词并计算分数
- 第三步:对于每一次的2个假设,找出最前面的2个单词进行分支保留
在$t=2$这个时刻,保留分数最高的hit和was两个单词
Beam search decoding: finishing up
在beam search的过程中,不同路径预测输出结束标志符
当beam search结束时,需要从n条完全路径中选一个打分最高的路径作为最终结果。由于不同路径的长度不一样,而beam search打分是累加项,累加越多打分越低,所以需要用长度对打分进行归一化。
那么,为什么不在beam search的过程中就直接用下面的归一化打分来比较呢?因为在树搜索的过程中,每一时刻比较的两条路径的长度是一样的,即分母是一样的,所以归一化打分和非归一化打分的大小关系是一样的,即在beam search的过程中就没必要对打分进行归一化。
Advantages and Disadvantages of NMT
Advantages of NMT
- 性能更好,翻译更流程,RNN擅长语言模型,能更好的利用上下文关系,能利用短语相似性
- 模型更简单,只需要一个神经网络,端到端训练即可,简单方便
- 不需要很多的人工干预和特征工程,对于不同的语言,网络结构保持一样,只需要换一下词向量
Disadvantages of NMT
- 难以解释,难以调试,难以解释出错原因
- 难以控制,比如难以加入一些人工的规则
How do we evaluate Machine Translation?
BLEU(Bilingual Evaluation Understudy)衡量机器翻译结果和人类的翻译结果(标注答案)的n-gram的overlap,overlap越多,打分越高。BLEU很有用,但不完美,因为一个句子有很多不同的翻译办法,所以一个好的翻译可以得到一个糟糕的BLEU score,因为它与人工翻译的n-gram重叠较低。
Section 3: Attention
此部分关于attention的原理和应用阐述一部分来自这篇文章——彻底搞懂BERT。
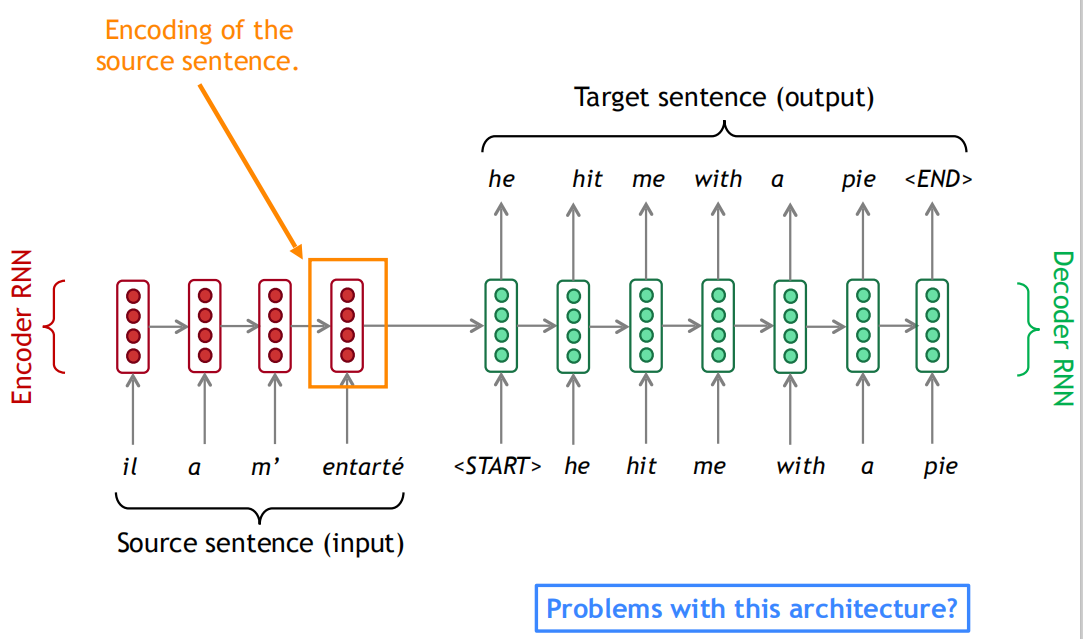
最后介绍提升机器翻译性能的一大利器——注意力机制Attention。首先回顾一下朴素的seq2seq模型,我们用Encoder RNN的最后一个神经元的隐状态作为Decoder RNN的初始隐状态,也就是说Encoder的最后一个隐状态向量需要承载源句子的所有信息,成为整个模型的“信息”瓶颈。
在encode阶段,第一个节点输入一个词,之后的节点输入的是下一个词与前一个节点的hidden state,最终encoder会输出一个context,这个context又作为decoder的输入,每经过一个decoder的节点就输出一个翻译后的词,并把decoder的hidden state作为下一层的输入。该模型对于短文本的翻译来说效果很好,但是其也存在一定的缺点,如果文本稍长一些,就很容易丢失文本的一些信息,为了解决这个问题,Attention应运而生。
Sequence-to-sequence with attention
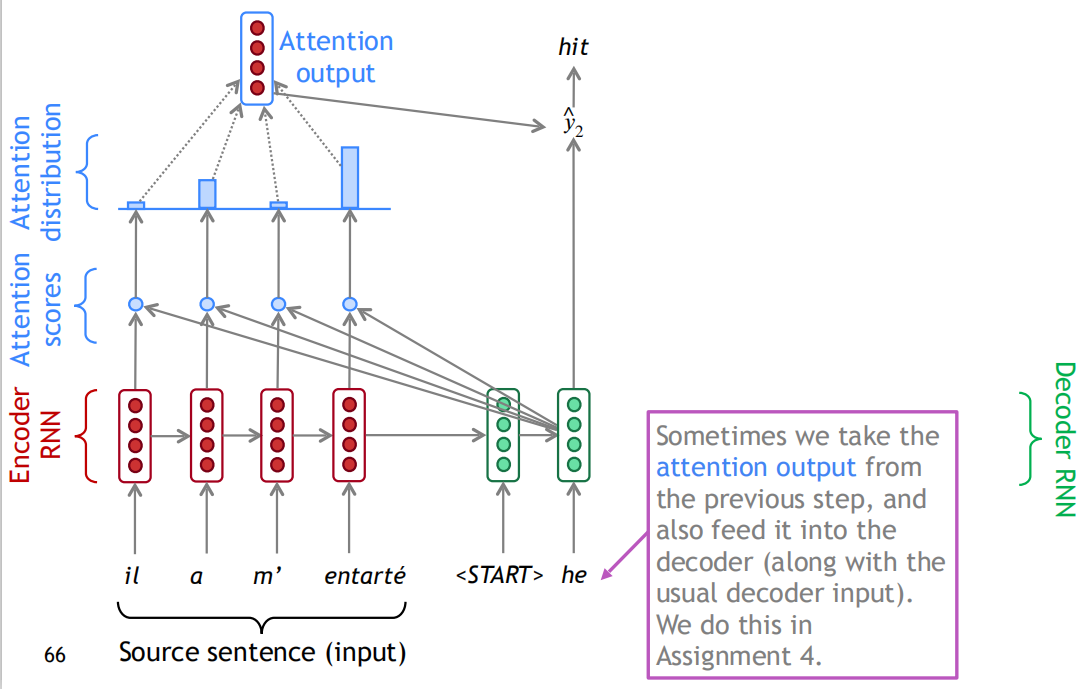
Attention机制就是为了解决这个“信息”瓶颈而设计的。Attention把Decoder RNN的每个隐层和Encoder RNN的每个隐层直接连起来了,由于有这个捷径,Encoder RNN的最后一个隐状态不再是“信息”瓶颈,信息还可以通过Attention的很多“直连”线路进行传输。
具体来说,在$t$时刻,Decoder第$t$时刻的隐状态$s_t$和Encoder所有时刻的隐状态$h_1,…,h_N$做点积,得到N个标量Attention score,作为Encoder每个隐状态的权重,然后使用softmax对这些权重进行归一化,得到Attention distribution。这个Attention distribution相当于Decoder在时刻对Encoder所有隐状态的注意力分布,如下图所示,翻译到”he”这个时刻的注意力主要分布在Encoder的第2和第4个词上,这就是SMT的对齐操作,Attention自动学习到了这种对齐操作,只不过是soft alignment。接下来,对Encoder所有隐状态使用Attention distribution进行加权平均,得到Attention output$a_t$。把$a_t$和该时刻的隐状态$s_t$拼起来再进行非线性变换得到输出$\hat{y}_2$
。有时,也可以把上一时刻的Attention output和当前的输入词向量拼起来作为一个新的输入,输入到Decoder RNN中。
encoder提供了更多的数据给到decoder,encoder会把所有的节点的hidden state提供给decoder,而不仅仅只是encoder最后一个节点的hidden state。
decoder并不是直接把所有encoder提供的hidden state作为输入,而是采取一种选择机制,把最符合当前位置的hidden state选出来,具体的步骤如下:
- 确定哪一个hidden state与当前节点关系最为密切
- 计算每一个hidden state的分数值
- 对每个分数值做一个softmax的计算,这能让相关性高的hidden state的分数值更大,相关性低的hidden state的分数值更低
这里我们以一个具体的例子来看下其中的详细计算步骤:
把每一个encoder节点的hidden states的值与decoder当前节点的上一个节点的hidden state相乘,如上图,h1、h2、h3分别与当前节点的上一节点的hidden state进行相乘(如果是第一个decoder节点,需要随机初始化一个hidden state),最后会获得三个值,这三个值就是上文提到的hidden state的分数,注意,这个数值对于每一个encoder的节点来说是不一样的,把该分数值进行softmax计算,计算之后的值就是每一个encoder节点的hidden states对于当前节点的权重,把权重与原hidden states相乘并相加,得到的结果即是当前节点的hidden state。可以发现,其实Atttention的关键就是计算这个分值。
明白每一个节点是怎么获取hidden state之后,接下来就是decoder层的工作原理了,其具体过程如下:
第一个decoder的节点初始化一个向量,并计算当前节点的hidden state,把该hidden state作为第一个节点的输入,经过RNN节点后得到一个新的hidden state与输出值。注意,这里和Seq2Seq有一个很大的区别,Seq2Seq是直接把输出值作为当前节点的输出,但是Attention会把该值与hidden state做一个连接,并把连接好的值作为context,并送入一个前馈神经网络,最终当前节点的输出内容由该网络决定,重复以上步骤,直到所有decoder的节点都输出相应内容。

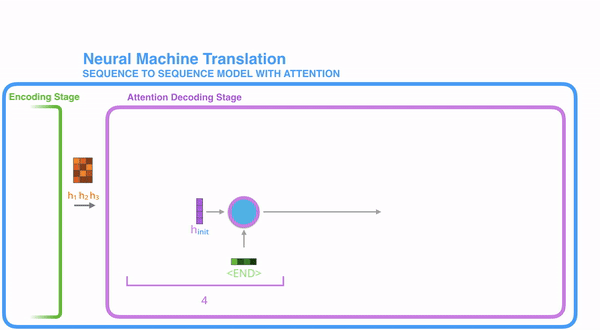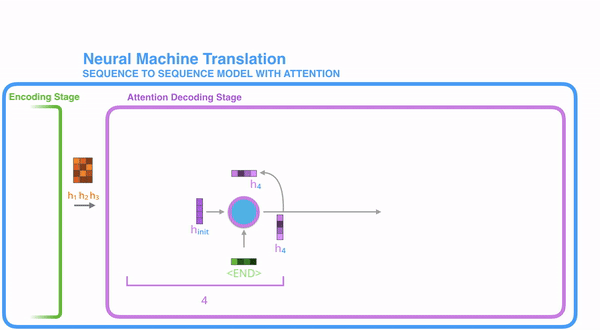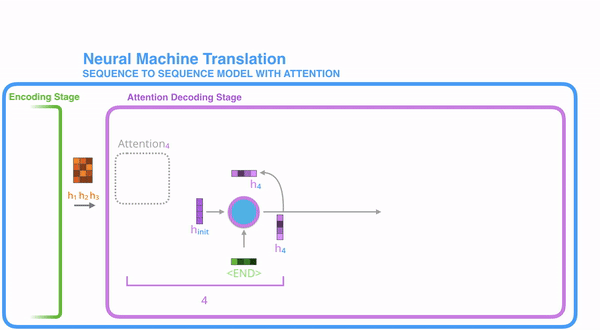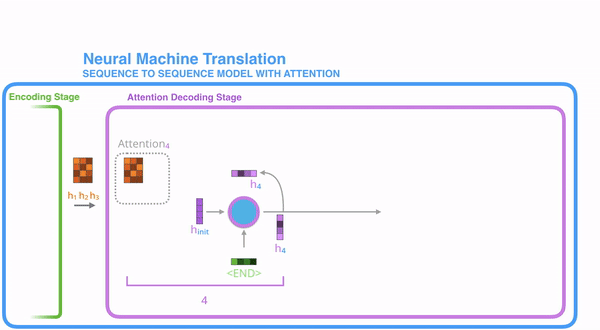
Attention: in equations
- 在$t$时刻上,我们有编码器隐藏状态$h_1,…,h_N\in\mathbb{R}^h$
- 我们有解码器隐藏状态$s_t\in\mathbb{R}^h$
- 我们得到这一步的注意分数
- 我们使用softmax得到这一步的注意分布$\alpha^t$
- 我们使用$\alpha^t$来获得编码器隐藏状态的加权和,得到注意力输出$a_t$
- 最后,我们将注意力输出$a_t$与解码器隐藏状态连接起来,并按照非注意seq2seq模型继续进行
Attention is great
- 提高NMT性能,让Decoder更多的关注于时刻$t$需要翻译的词
- 解决了NMT的“信息”瓶颈问题
- 有助于缓解梯度消失问题,因为Decoder的每一时间步都和所有Encoder的隐状态相连了
- 有助于增加NMT的可解释性,解释为什么时刻$t$翻译输出了某个词,可以通过查看Attentioin distribution来解释
There are several attention variants
现在,Attention已经变成了深度学习的一个的通用技术,并不局限于seq2seq和机器翻译。Attention更一般的过程:

Attention variants
Attention还有很多变种,都是在query和values怎样相乘得到Attention scores上做文章

- 基本的点乘注意力
- 乘法注意力
- 加法注意力