
Vanishing gradient intuition
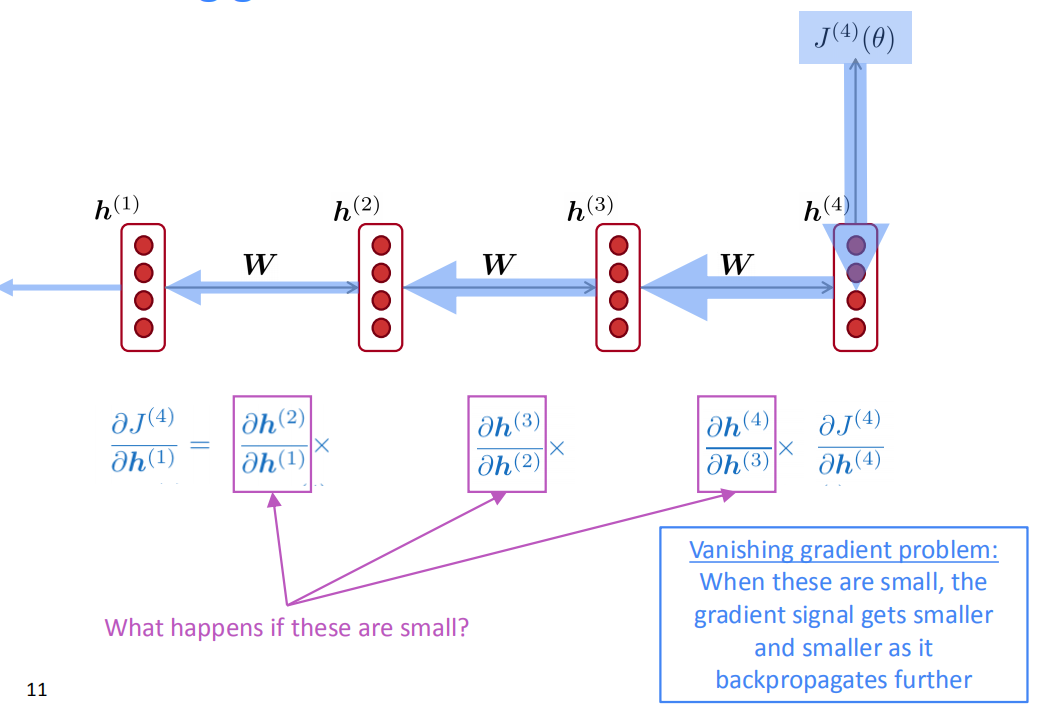
RNN在不同时都使用共享参数$W$,导致$t+n$时刻的损失对$t$时刻的参数的偏导数存在$W$的指数形式,一旦$W$很小就会导致梯度消失问题。当这些梯度很小的时候,反向传播的越深入,梯度信号就会变得越来越小
Why is vanishing gradient a problem?
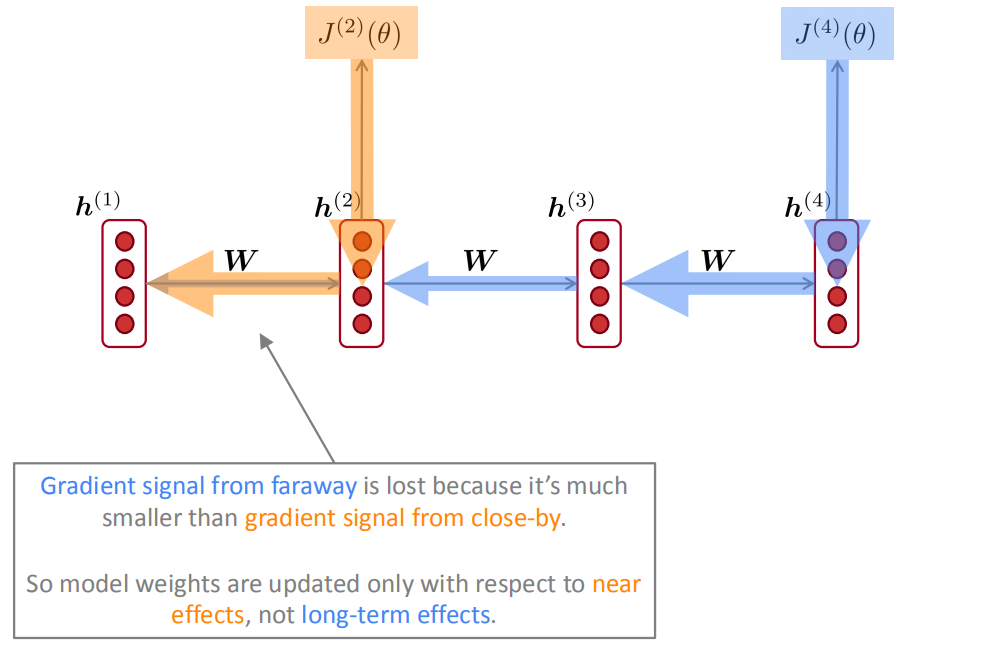
在nlp任务中,梯度消失会使得参数更新更多的受到临近词的影响,那些和当前$t$时刻较远的词对当前的参数更新影响很小。上图中$h^{(1)}$对$J^{(2)}(\theta)$的影响就比对$J^{(4)}(\theta)$的影响大。久而久之,因为梯度消失,我们就不知道$t$时刻是真的对$t+n$时刻没影响还是因为梯度消失导致我们没学习到这种影响
Effect of vanishing gradient on RNN-LM

由于梯度的消失,RNN-LMs更善于从顺序近因学习而不是语法近因 ,所以他们犯这种错误的频率比我们希望的要高,假设我们需要预测句子The writer of the books下一个单词,由于梯度消失,books对下一个词的影响比writer对下一个词的影响更大,导致模型错误的预测成了are
Why is exploding gradient a problem?
如果梯度爆炸,则根据梯度下降的更新公式,参数会一瞬间更新非常大,导致网络震荡,甚至出现Inf或NaN的情况
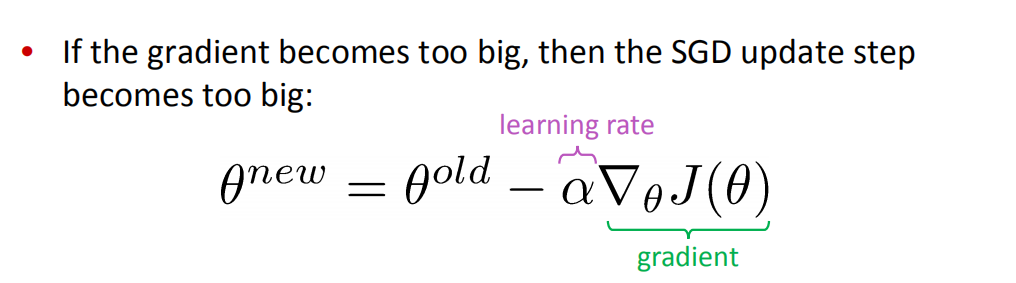
Gradient clipping: solution for exploding gradient

- 梯度裁剪 :如果梯度的范数大于某个阈值,在应用SGD更新之前将其缩小
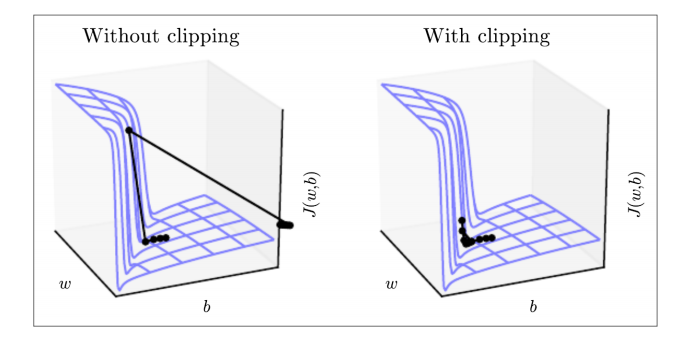
左图是没有梯度裁剪的情况,由于RNN的梯度爆炸问题,导致快接近局部极小值时,梯度很大,参数突然爬上悬崖,然后又飞到右边一个随机的区域,绕过了中间的局部极小值。右图是增加了梯度裁剪之后,更新步伐变小,参数稳定在局部极小值附近
梯度爆炸相对好解决,想要解决梯度消失,就要靠一个具有独立记忆的RNN
Long Short-Term Memory (LSTM)
- LSTM在1997年提出用于解决梯度消失问题
- 信息被遗忘/写入/读取的选择由三个对应的门控制
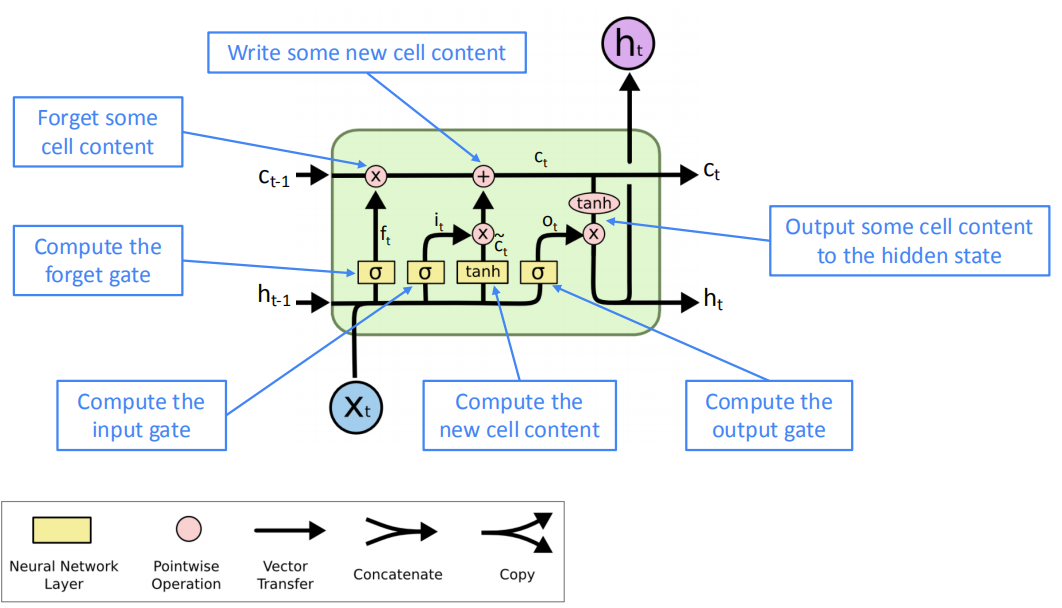
LSTM的隐层不仅包含隐状态$h_t$,还专门开辟了一个cell来保存过去的“记忆”$c_t$,LSTM希望用$c_t$来传递很久以前的信息,以达到长距离依赖的目的。所以LSTM隐层神经元的输入是上一时刻的隐状态$h_{t-1}$和记忆$c_{t-1}$,输出是当前时刻的隐状态$h_t$和希望传递给下一个时刻的记忆$c_t$。
- 遗忘门:控制上一个单元状态的保存与遗忘
- 输入门:控制写入单元格的新单元内容的哪些部分
- 输出门:控制单元的哪些内容输出到隐藏状态
- 单元状态:删除(“忘记”)上次单元状态中的一些内容,并写入(“输入”)一些新的单元内容
- 隐藏状态:从单元中读取(“output”)一些内容
- Sigmoid函数:所有的门的值都在0到1之间
- 通过逐元素的乘积来应用门
- 这些是长度相同的向量
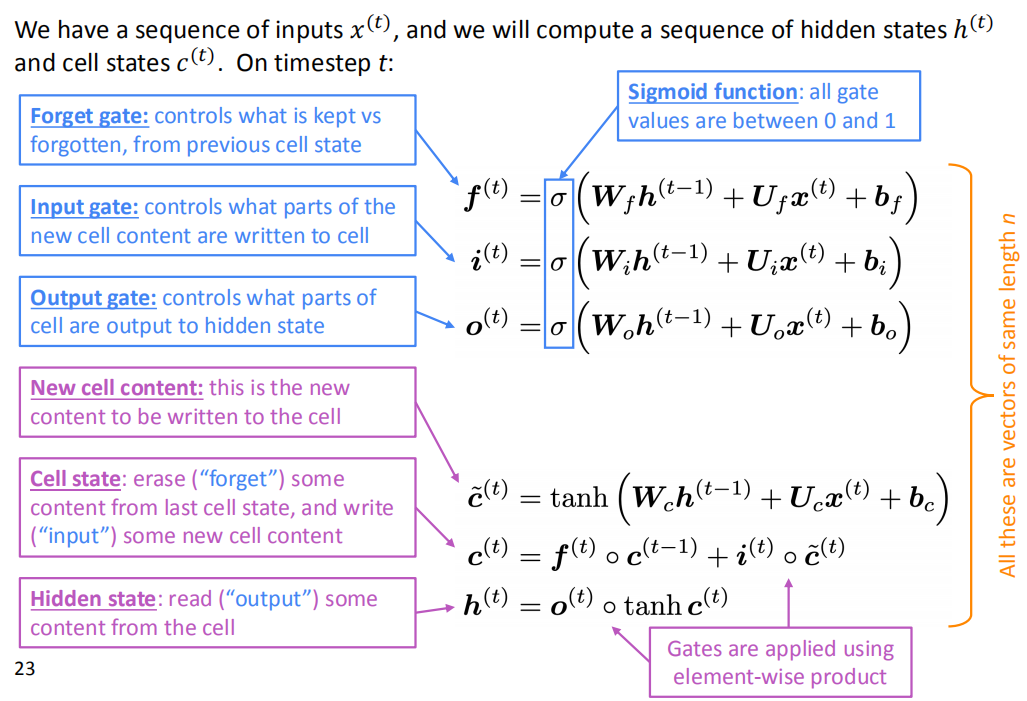
我们有一个输入序列$x^{(t)}$,我们将计算一个隐藏状态$h^{(t)}$和单元状态$c^{(t)}$的序列。在$t$时刻时为了调控遗忘哪些记忆,写入哪些新记忆,LSTM设置了两个门,分别是遗忘门$f^{(t)}$和输入门$i^{(t)}$,它们都是上一时刻的隐状态$h_{t-1}$和当前时刻的输入$x^{(t)}$经过Sigmoid函数输出的结果。
- $f^{(t)}$控制遗忘哪些记忆:$f^{(t)}\cdot c^{(t-1)}$
- $i^{(t)}$控制写入哪些新记忆:$i^{(t)}\cdot\tilde{c}^{(t)}$,其中$\tilde{c}^{(t)}$即为期望写入的新记忆,它是隐状态$h_{t-1}$和当前时刻的输入$x^{(t)}$经过Tanh函数输出的结果
最终,新时刻$t$的记忆就是这两部分的组合
- 输出门$o^{(t)}$控制哪些记忆需要输出到下一个隐状态$h^{(t)}$,$o^{(t)}$也是隐状态$h_{t-1}$和当前时刻的输入$x^{(t)}$经过Sigmoid函数输出的结果。
How does LSTM solve vanishing gradients?
LSTM解决梯度消失最直接的方法就是,遗忘门选择不遗忘,每一时刻遗忘门$f^{(t)}$都选择记住前一时刻的记忆$c^{(t-1)}$,然后直接传递给下一时刻。那么,所有前$t-1$时刻的记忆都会被完整的传递给第$t$时刻,从而对时刻的输出产生影响。LSTM依然存在梯度消失或梯度爆炸问题,但是这两种情况得以缓解,且LSTM性能不错。
LSTMs: real-world success
2013-2015年,LSTM开始实现最先进的结果,成功的任务包括:手写识别、语音识别、机器翻译、解析、图像字幕。现在(2020年),其他方法(如Transformers)在某些任务上变得更加主导。
Gated Recurrent Units (GRU)
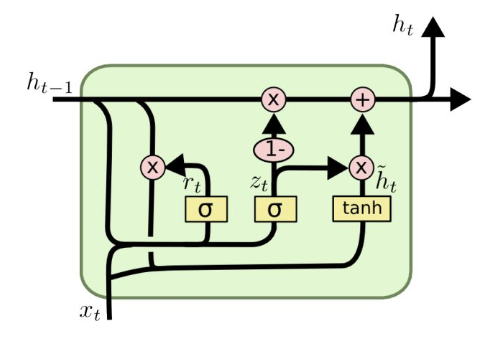
- 更新门:控制隐藏状态的哪些部分被更新,哪些部分被保留
- 重置门:控制之前隐藏状态的哪些部分被用于计算新内容
原课件没有提供GRU的结构示意图,找了一个网上的,上图中的$z_t$对应下面的$u^{(t)}$,其他的将下角标改为上角标对待
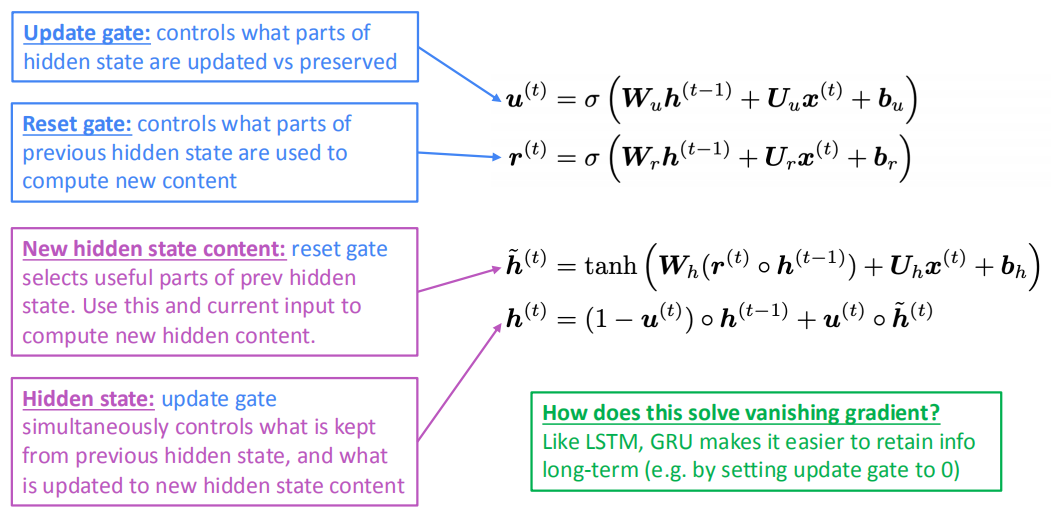
GRU没有cell,但依然保留了门来控制信息的传递。当前时刻的隐状态$h^{(t)}$等于上一时刻的隐状态$h^{(t-1)}$和新写入的隐状态$\tilde{h}^{(t)}$
的加权平均,更新门$u^{(t)}$来控制它们之间的比例,$u^{(t)}$是上一个时刻的隐状态$h_{t-1}$和当前时刻的输入$x^{(t)}$经过Sigmoid函数输出的结果。新写入的隐状态$\tilde{h}^{(t)}$通过一个重置门$r^{(t)}$来控制,它也是$h_{t-1}$和$x^{(t)}$经过Sigmoid函数输出的结果。
GRU中的更新门$u^{(t)}$类似于LSTM中的输出门$o^{(t)}$,重置门$r^{(t)}$类似于LSTM中的遗忘门$f^{(t)}$和输入门$i^{(t)}$的组合,GRU中新写入的隐状态$\tilde{h}^{(t)}$类似于LSTM中的记忆$c^{(t)}$
LSTM vs GRU
- 研究人员提出了许多门控RNN变体,其中LSTM和GRU的应用最为广泛
- 最大的区别是GRU计算速度更快,参数更少
- 没有确凿的证据表明其中一个总是比另一个表现得更好
- LSTM是一个很好的默认选择(特别是当您的数据具有非常长的依赖关系,或者您有很多训练数据时)
- 可以根据经验法则:从LSTM开始,但是如果你想要更有效率,就切换到GRU
Is vanishing/exploding gradient just a RNN problem?
对于所有的神经结构(包括前馈和卷积)都是一个问题,尤其是对于深度结构,一些通用解决方法如下:
ResNet
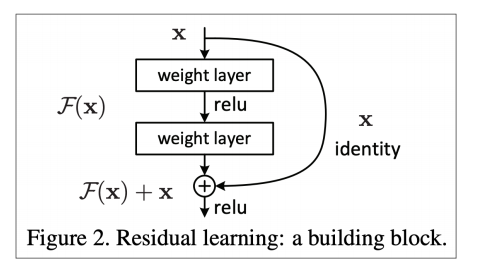
因为梯度是在传递的过程中逐渐减小并消失的,如果跨越好几层直接进行连接,能保持远距离信息。
DenseNet
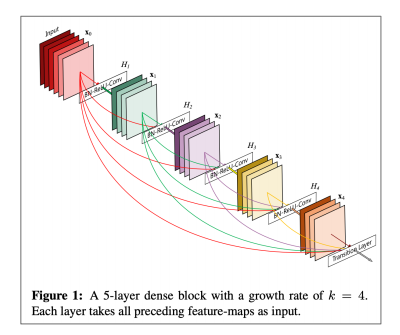
粗暴的把跨越多层之间的很多神经元都连起来,进一步减弱梯度消失问题。
HighwayNet
灵感来自LSTM,但适用于深度前馈/卷积网络,类似于剩余连接,但标识连接与转换层由动态门控制。

虽然所有神经网络都存在梯度消失的问题,但RNN的这个问题更严重,因为它连乘的是相同的权重矩阵W,而且RNN针对的是序列问题,往往更深。
Bidirectional RNNs
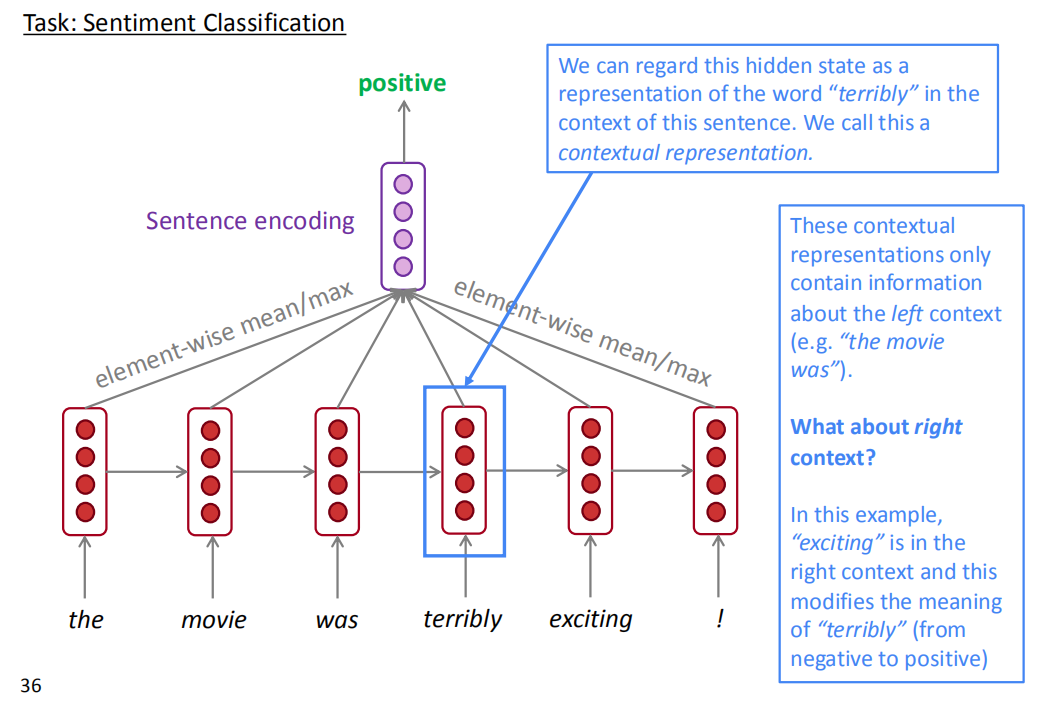
假设我们在对句子进行情感分类,如下图所示。对于terribly这个词,常规RNN,terribly的梯度只能看到左边的信息,看不到右边的信息,因为网络是从左到右的。单独看terribly或者从左往右看,在没有看到exciting时,可能认为terribly是贬义词,但是如果跟右边的exciting结合的话,则意思变为强烈的褒义词,所以有必要同时考虑左边和右边的信息。
双向RNN包含两个RNN,一个从左往右,一个从右往左,两个RNN的参数是独立的。最后把两个RNN的输出拼接起来作为整体输出。那么,对于terribly这个词,它的梯度能同时看到左边和右边的信息。
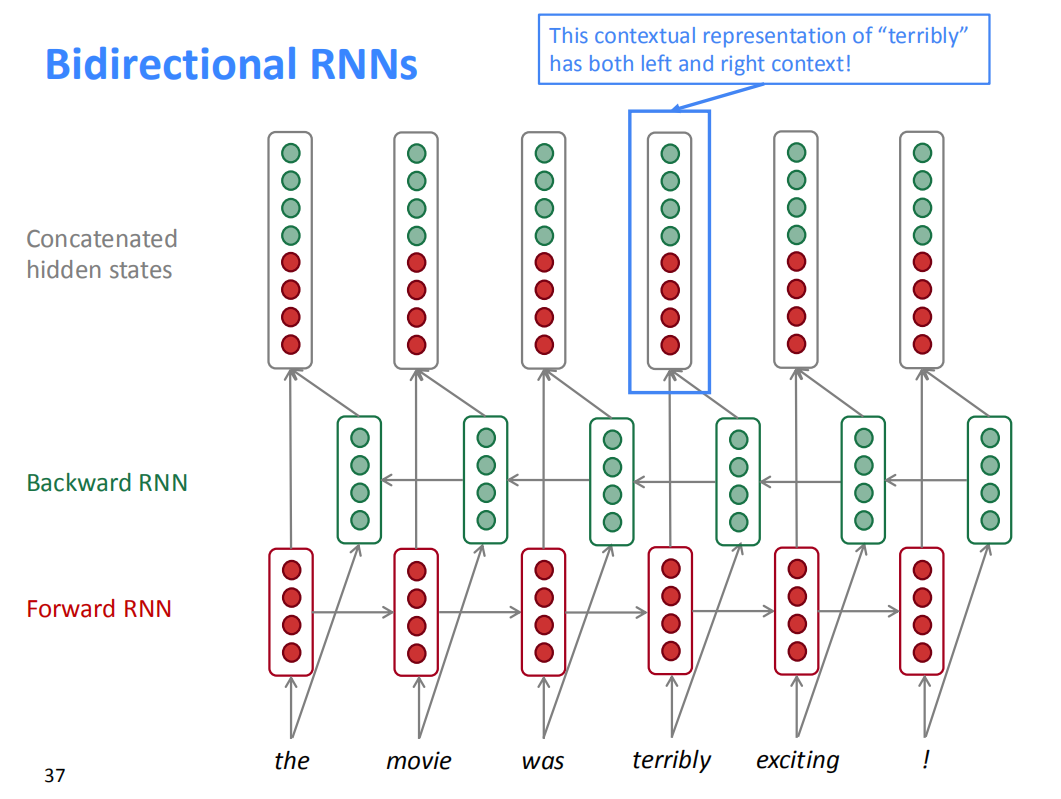
由于双向RNN对于某个时刻$t$,既需要知道时刻前的信息(Forward RNN),又需要知道时刻$t$之后的信息(Backward RNN),所以双向RNN无法用于学习语言模型,因为语言模型只知道时刻之前的信息,下一时刻的词需要模型来预测。对于包含完整序列的NLP问题,双向RNN应该是默认选择,它通常比单向RNN效果更好。
Multi-layer RNNs
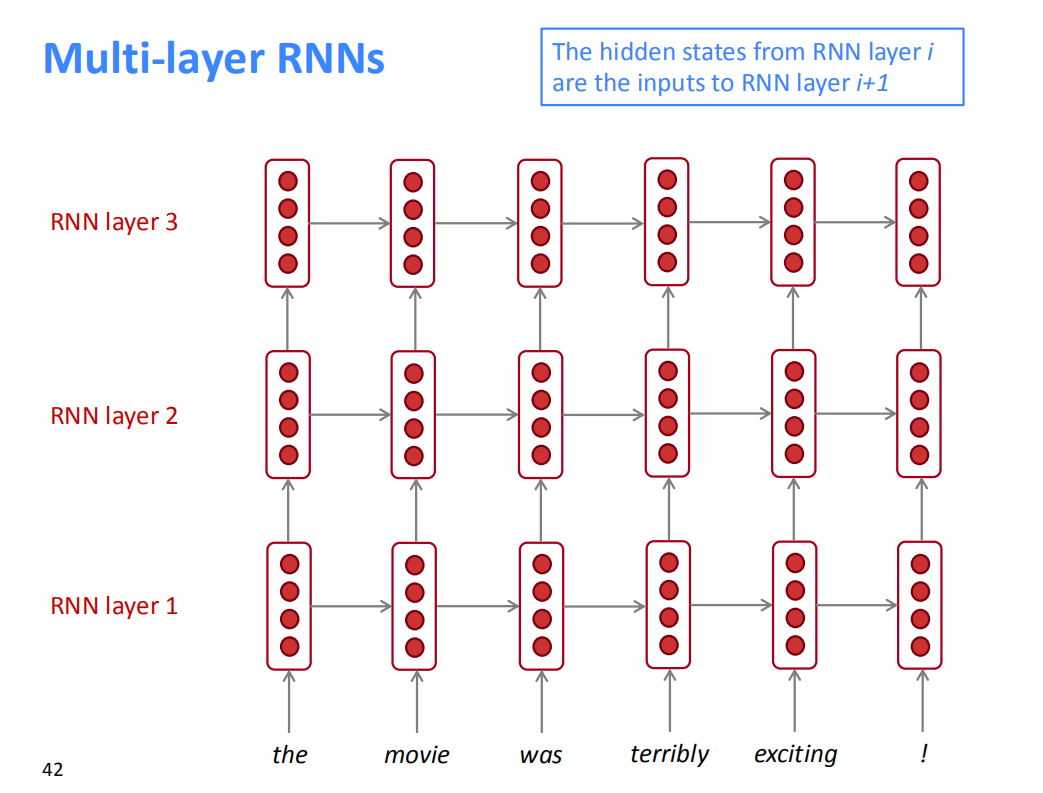
前面展示的RNN从时间的维度上来说可以认为是多层的,但是RNN还可以从另一个维度来增加层数。将上一层(RNN layer 1)的输出作为下一层(RNN layer 2)的输入,不断堆叠下去,变成一个多层RNN。通常来说,深度越大,性能越好,但是他的缺点是RNN无法并行化,计算代价过大,所以不会过深