
Language Modeling
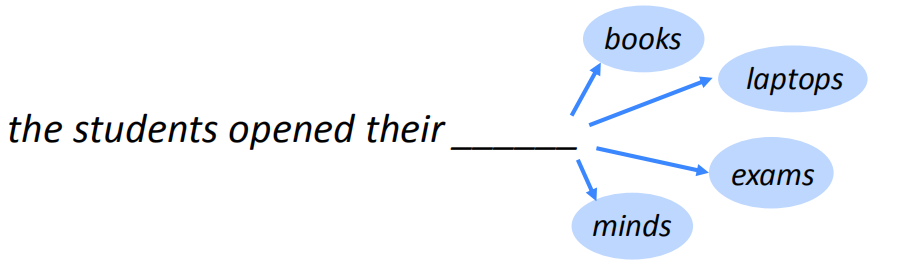
语言模型就是预测一个句子中下一个词的概率分布。如上图所示,假设给定一个句子前缀是the students opened their,语言模型预测这个句子片段下一个词是books、laptops、exams、minds或者其他任意一个词的概率。形式化表示就是计算。
$x^{(t+1)}$表示第$t+1$个位置(时刻)的词是$x$,$x$可以是词典$V$中任意的一个词。
例如有一段文本$x^{(1)}$,…,$x^{(T)}$,则这段文本的概率(根据语言模型)为
语言模型可以用在输入法中预测下一个将要输入的词,在谷歌搜索中输入前几个关键词,搜索引擎会自动预测接下来可能的几个词。网上有很多智能AI自动生成新闻、诗歌等等。可以说语言模型是很多NLP任务的基础模块,具有非常重要的作用。
n-gram Language Models
在前-深度学习时代,人们使用n-gram方法来学习语言模型。对于一个句子,n-gram表示句子中连续的n个词,n-gram对于n=1,2,3,4的结果是:
- unigrams: “the”, “students”, “opened”, ”their”
- bigrams: “the students”, “students opened”, “opened their”
- trigrams: “the students opened”, “students opened their”
- 4-grams: “the students opened their”
n-gram方法有一个前提假设,即假设每个词出现的概率只和前n-1个词有关。n-gram的计算方法就是,统计语料库中出现$x^{(t)},…,x^{(t-n+2)}$的次数作为分母,以及在这个基础上再接一个词$x^{(t+1)}$的次数$x^{(t+1)},x^{(t)},…,x^{(t-n+2)}$作为分子,用后者除以前者来近似这个条件概率。
举个例子,假设完整的句子是as the proctor started the clock, the students opened their,需要预测下一个词的概率分布。对于4-gram方法,则只有students opened their对下一个词有影响,前面的词都没有影响。然后我们统计训练集语料库中发现,分母students opened their出现1000次,其后接books即students opened their books出现了400次,所以P(books|students opened their)=400/1000=0.4。类似的,可以算出下一个词为exams的概率是0.1。所以4-gram方法认为下一个词是books的概率更大。

n-gram方法在统计语料库中的n-gram时,对词的顺序是有要求的,即必须要和给定的n-gram的顺序一样才能对频数加1,比如这个例子中只有出现和students opened their顺序一样才行,如果是their students opened则不行。
n-gram方法虽然能够有效,比如对于上面的例子,预测出books和exams看起来和前面几个词搭配得很好;但是,它有不少的问题,还是上面的例子,其实考虑更前面的词proctor以及clock的话,这很明显是考试场景,后面出现exams的概率应该比books更高才对。
具体来说,n-gram方法有以下不足:
- 考虑的状态有限。n-gram只能看到前n-1个词,无法建模长距离依赖关系,上面就是一个很好的例子。
- 稀疏性问题。对于一个稀有的(不常见的)词w,如果他的词组没有在语料库中出现,则分子为0,但w很有可能是正确的,概率至少不是0。比如students opened their petri dishes,对于学生物的学生来说是有可能的,但如果students opened their petri dishes没有在语料库中出现的话,petri dishes的概率就被预测为0了,这是不合理的。当然这个问题可以通过对词典中所有可能的词组频率+1平滑来部分解决。
- 更严重的稀疏性问题,如果分母的词组频率在语料库中是0,那么所有词w对应的分子的词组频率就是0了,根本就没法计算概率。这种情况只能使用back-off策略,即如果4-gram太过于稀疏了,则降到3-gram,分母只统计opened their的频率。一般的,虽然n-gram中的n越大,语言模型预测越准确,但其稀疏性越严重。n其实就相当于维度,我们知道在空间中,维度越高越稀疏,高维空间非常稀疏。对于n-gram,一般取n<=5。
- 存储问题,需要存储所有n-gram的频率,如果n越大,这种n-gram的组合越多,所以存储空间呈幂次上升。
下面是一个更直观的trigram稀疏性问题的例子,由于语料库中统计到的today the company和today the bank的词组频率相同,导致company和bank算出来的概率相等,无法区分。就是因为这两个trigram在预料中出现都比较少,很稀疏,导致统计数据难以把他们区分开来。

A fixed-window neural Language Model
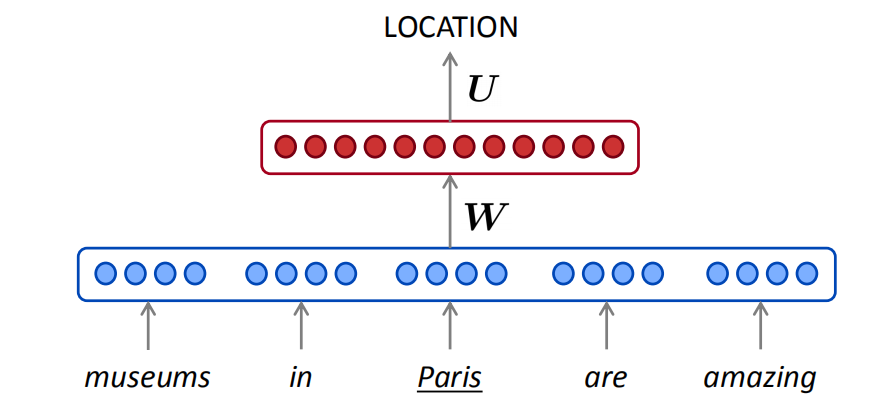
window-based neural model在第三讲中被用于NER问题,方法是对一个词开一个小窗口,然后利用词向量和全连接网络识别词的类别。仿照这个方法,也可以用基于窗口的方法来学习语言模型。
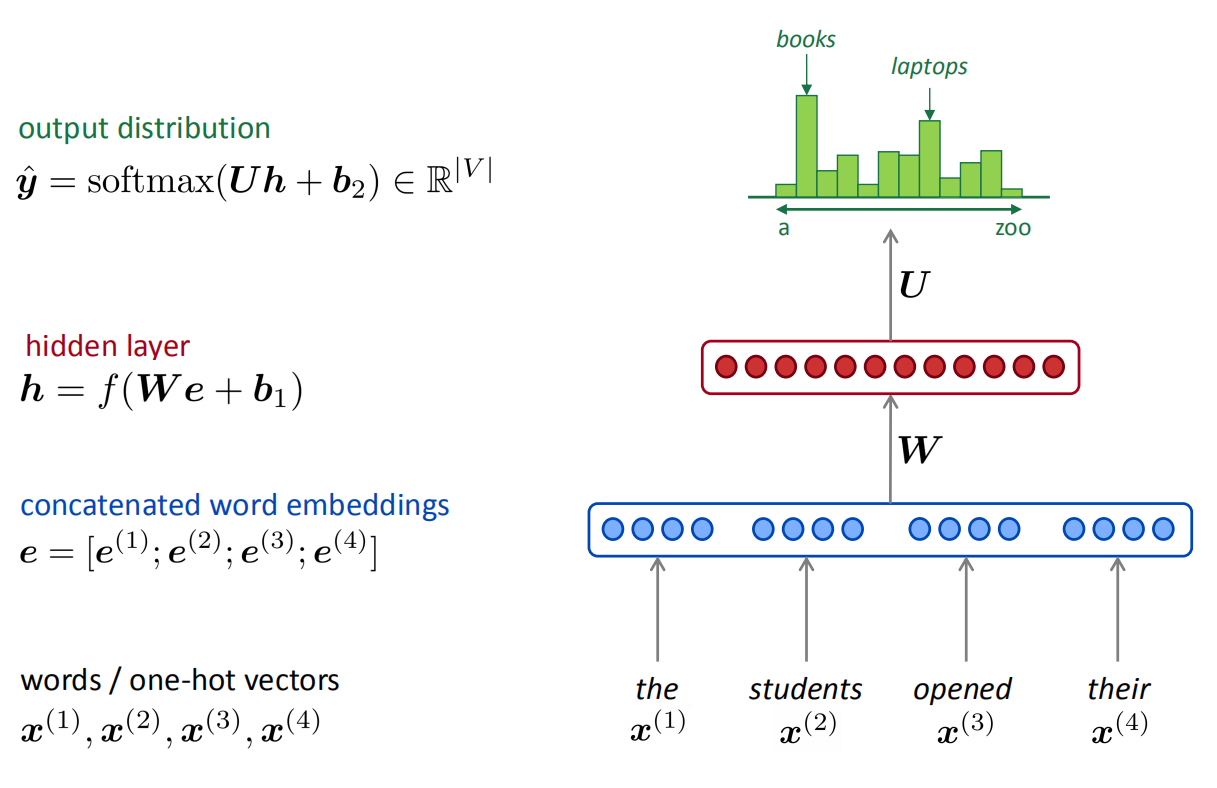
超越n-gram语言模型的改进有:
- 没有稀疏性问题,它不要求语料库中出现n-gram的词组,它仅仅是把每个独立的单词的词向量组合起来。只要有词向量,就有输入,至少整个模型能顺利跑通。
- 不需要观察到所有的n-grams,节省存储空间,只需要存储每个独立的词的词向量。
存在的问题:
- 固定窗口太小,受限于窗口大小,不能感知远距离的关系。
- 扩大窗口就需要扩大权重矩阵$W$,导致网络变得复杂。
- 输入$e^{(1)},…,e^{(4)}$对应$W$的不同列,每个$e$对应的权重完全是独立的,没有共享关系,导致训练效率比较低。
我们需要一个神经结构,可以处理任何长度的输入
RNN Language Model
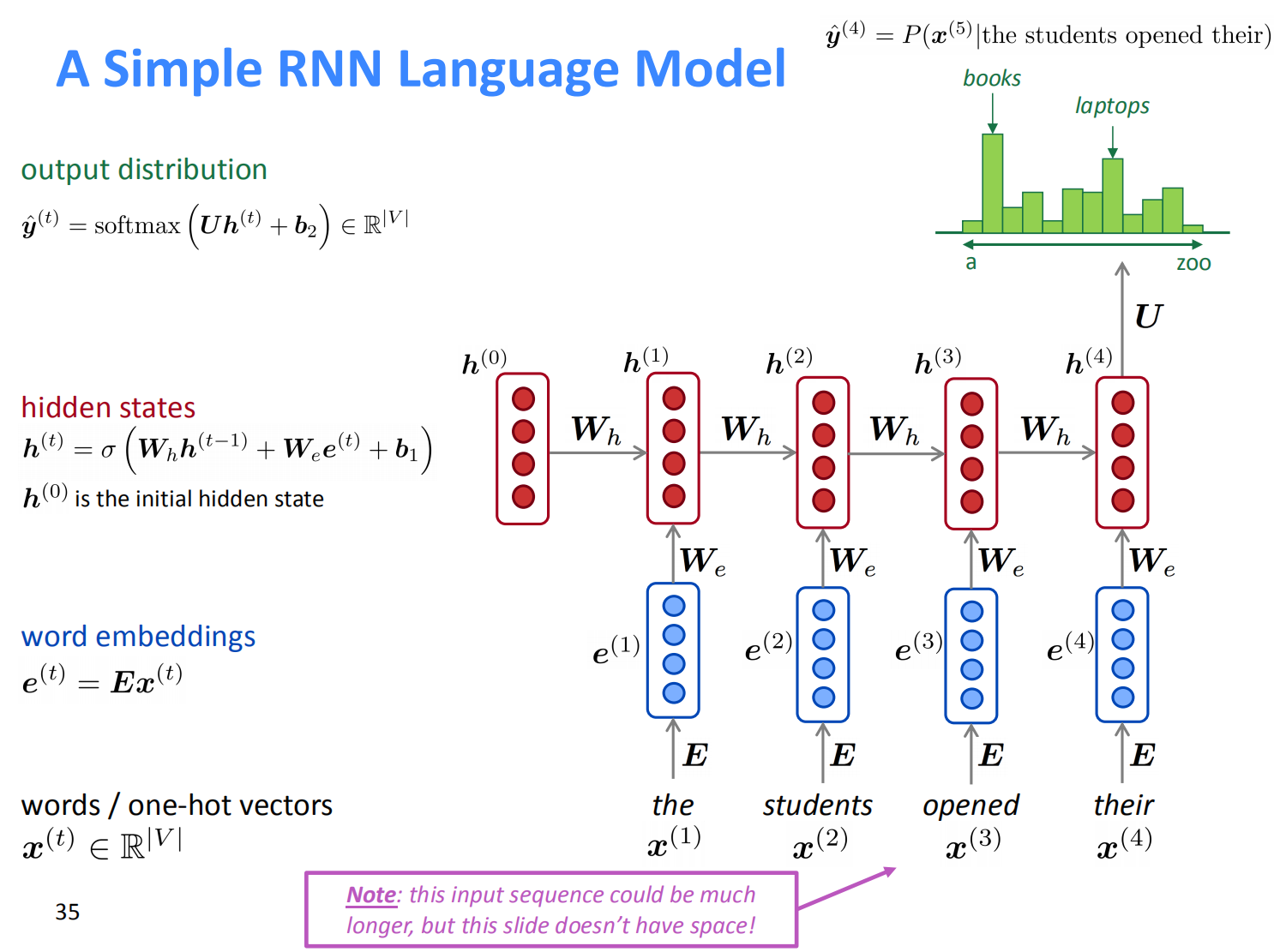
RNN输入可以是任意长度,特别适合对顺序敏感的序列问题进行建模。对于$t$时刻的输入词$x^{(t)}$来说,首先把它转为词向量$e^{(t)}$作为RNN的输入,然后对于隐藏层,它的输入来自于$t$时刻的输入变换$W_ee^{(t)}$和上一时刻的隐藏层变换$W_hh^{(t-1)}$,这两部分组合起来再做一个非线性变换,得到当前层的隐状态$h^{(t)}$,最后,隐状态再接一个softmax层,得到该时刻的输出概率分布$\hat{y}^{(t)}$
整个网络中,不同时刻的权重矩阵$W$是共享的,不同的是不同时刻的输入$x^{(t)}$和隐状态$h^{(t)}$,词向量$e$可以是pre-trained得到的,然后固定不动,也可以根据实际任务进行fine-tune,甚至可以完全随机,在实际任务中现场学习。常规任务中,最好还是用pre-trained的词向量,如果数据量很大的话,再考虑fine-tune
RNN的优点:
- 可以处理任意长度的输入
- 状态$t$可以感知很久以前的状态
- 模型大小是固定的,因为不同时刻的参数都是共享的
RNN的缺点:
- 训练起来很慢,因为后续状态需要用到前面的状态,是串行的,难以并行计算
- 虽然理论上$t$时刻可以感知很久以前的状态,但实际上很难,因为梯度消失的问题
Training a RNN Language Model
- 训练RNN依然是梯度下降,输入RNN-LM,计算每个时刻$t$的输出分布,即预测到目前为止给定的每个单词的概率分布。
- RNN在$t$时刻的输出是预测$t+1$个词的概率分布$\hat{y}^{(t)}$,而训练集中第$t+1$个词是已知的单词,所以真实答案$y^{(t)}$其实是一个one-hot向量,在第$x^{(t+1)}$的位置为1,其它位置为0,所以如果是交叉熵损失函数的话,表达式如下图中间的等式。
- RNN整体的损失就是所有时刻的损失均值。
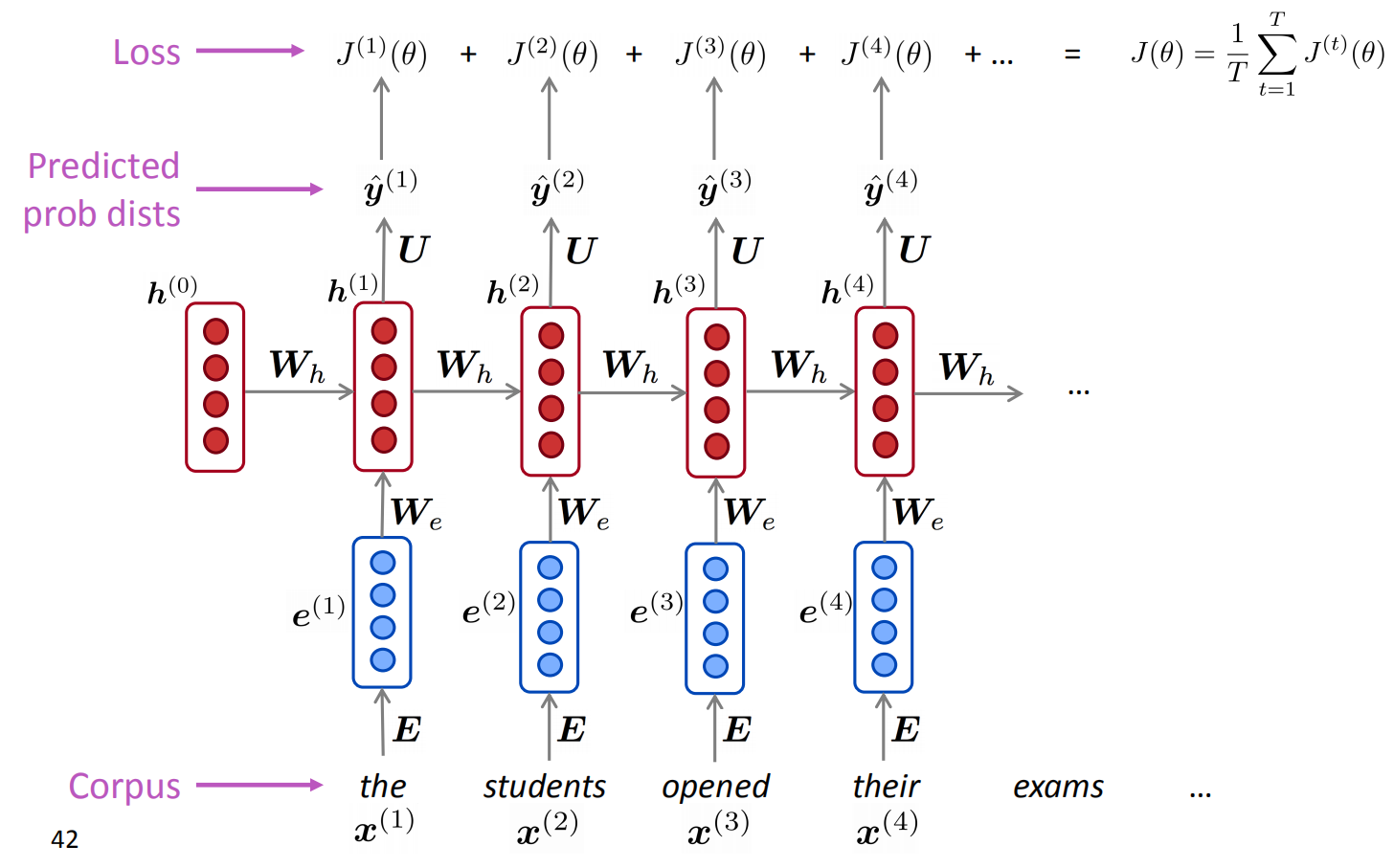
因为完整的语料库通常是非常大,比如上百万篇文章,这么长的输入,训练起来就很费劲,所以输入RNN的往往是以句子或者单篇文档为单位,然后使用SGD,小batch进行批量训练。
Backpropagation for RNNs
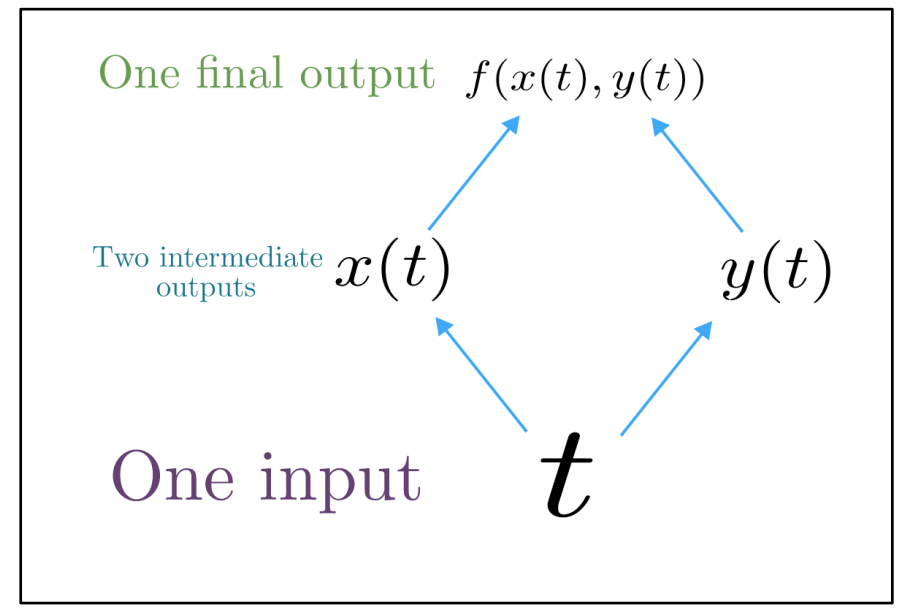
对于一个多变量函数$f(x,y)$和两个单变量函数$x(t)$和$y(t)$,其链式法则如下:
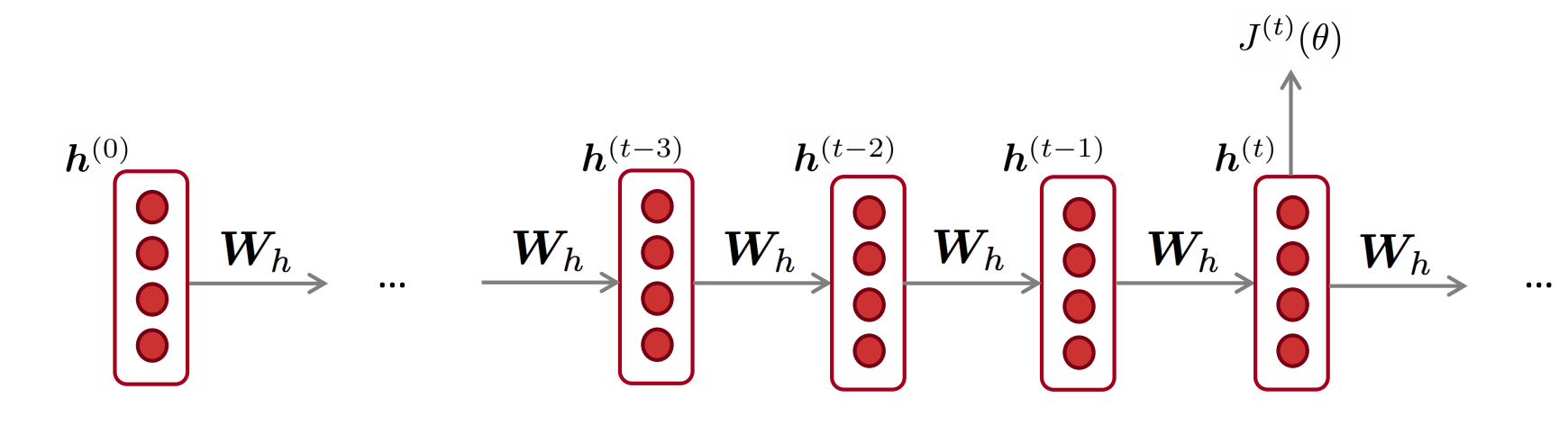
关于重复的权重矩阵$W_h$的偏导数$J^{(t)}(\theta)$是每次其出现时的梯度的总和
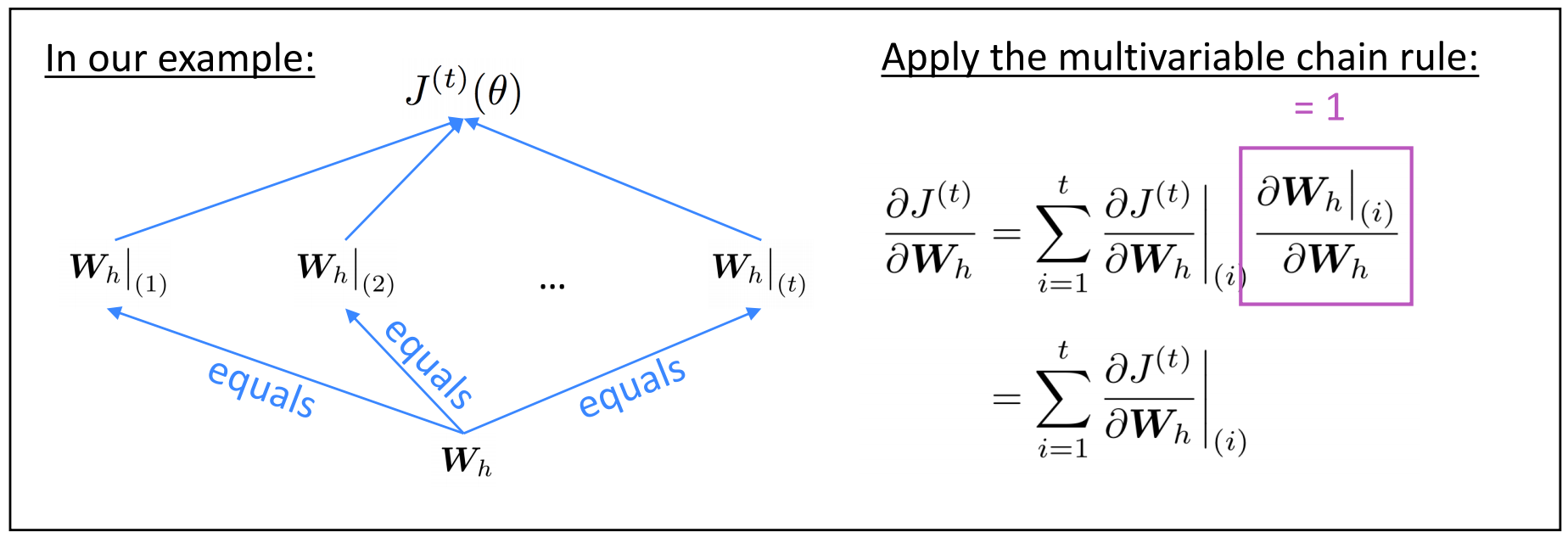
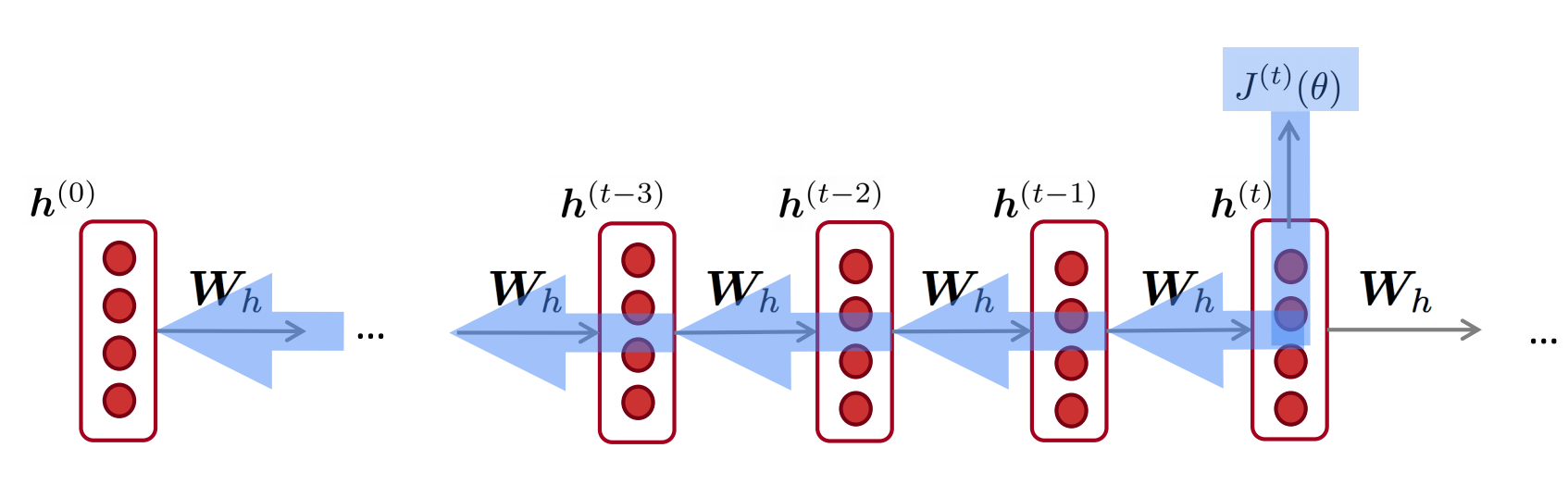
反向传播用时间步长计算累加梯度$i=t,…,0$。这个算法叫做“backpropagation through time”(BPTT)
Generating text with a RNN Language Model
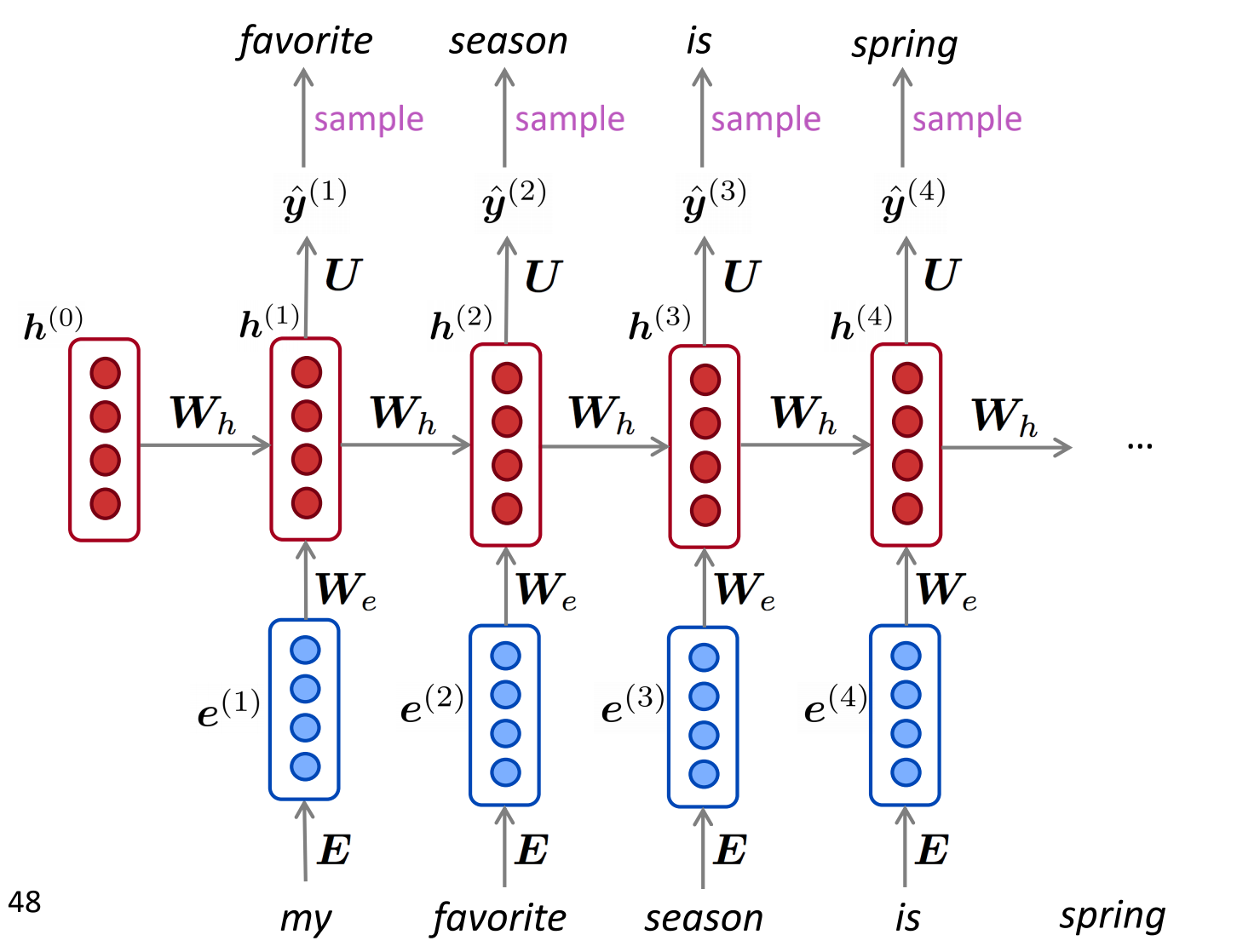
就像n-gram语言模型一样,可以使用RNN语言模型通过重复采样来生成文本。注意上一步的输出正好是下一步的输入,这样语义才连贯.
- 相比n-gram更流畅,语法正确,但总体上仍然很不连贯
- 食谱的例子中,生成的文本并没有记住文本的主题是什么
- 哈利波特的例子中,甚至有体现出了人物的特点,并且引号的开闭也没有出现问题(符号也有被神经元或者隐藏状态跟踪)
- RNN是否可以和手工规则结合?可以使用Beam Serach,但是可能很难做到
Evaluating Language Models
语言模型的评价指标是perplexity——困惑度,其计算公式如下。
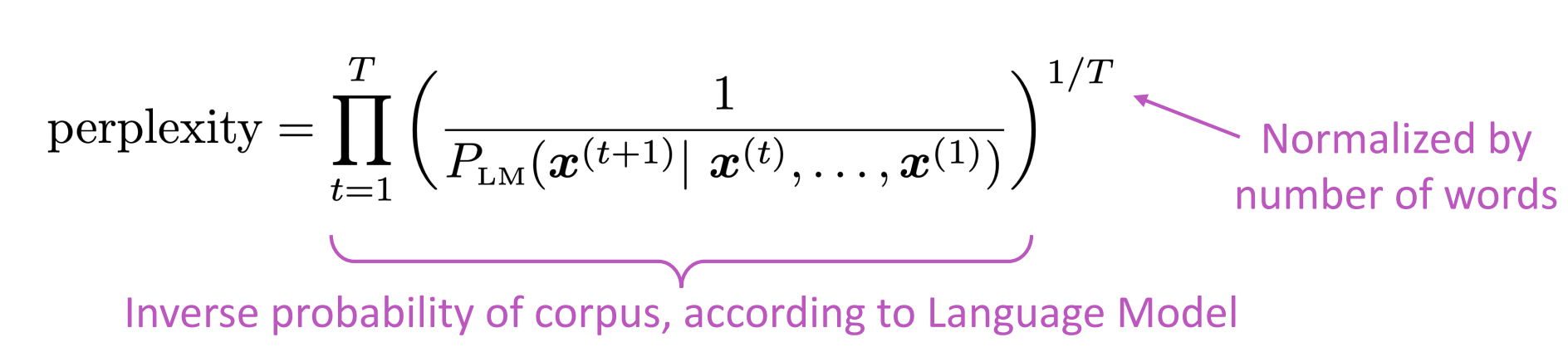
这等于交叉熵损失$J(θ)$的指数。困惑度和损失函数是正相关的,损失越低,则困惑度也越小,模型性能越好
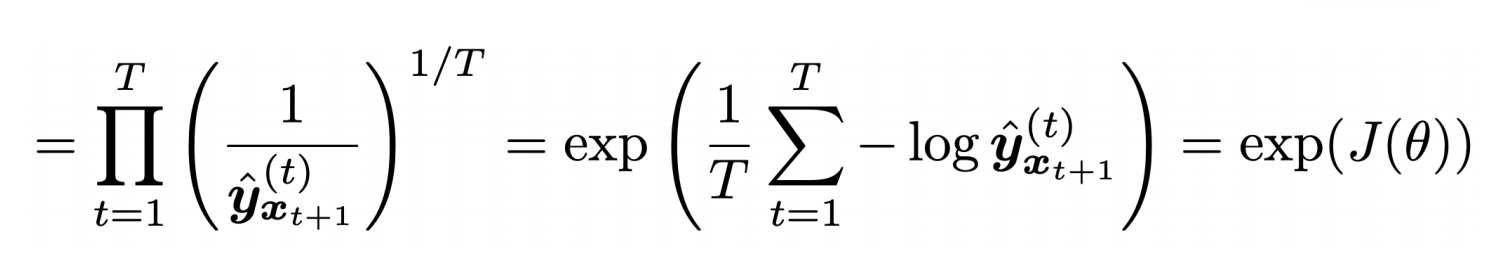
Why should we care about Language Modeling?
- RNNs can be used for tagging(词性标注, 命名实体识别)
- RNNs can be used for sentence classification(情感分类)
- Enbeddin编码(使用最终隐层状态或者使用所有隐层状态的逐元素最值或均值)
- RNNs can be used as an encoder module(机器翻译、问答等多中任务)
- RNN-LMs can be used to generate text(语音辨识, 机器翻译, 摘要生成)
RNN可保证上述的任务的基本实现。