
动机:我们的模型在做什么?
我们还不清楚算法学习到了什么功能,而且它们的复杂性使我们无法准确理解模型本身。
我们怎样才能使模型的效果更好呢?
一般认为对于神经网络,堆叠更多的层会获得更好的效果,但这完全是黑盒的,我们更加无法理解神经网络。
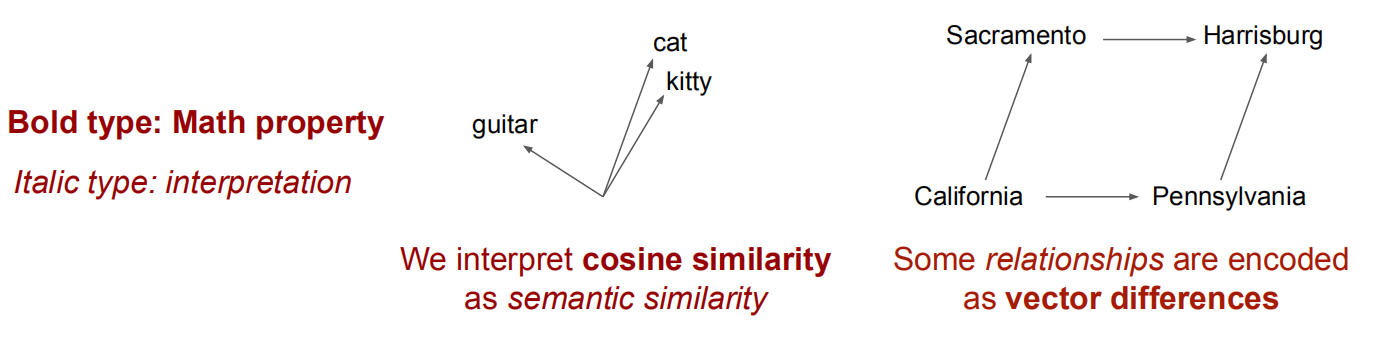
神经网络作为语言测试的主体
我们如何理解人类的语言行为?
一种方法:最小对立体。即什么对说话者来说是“好的”?
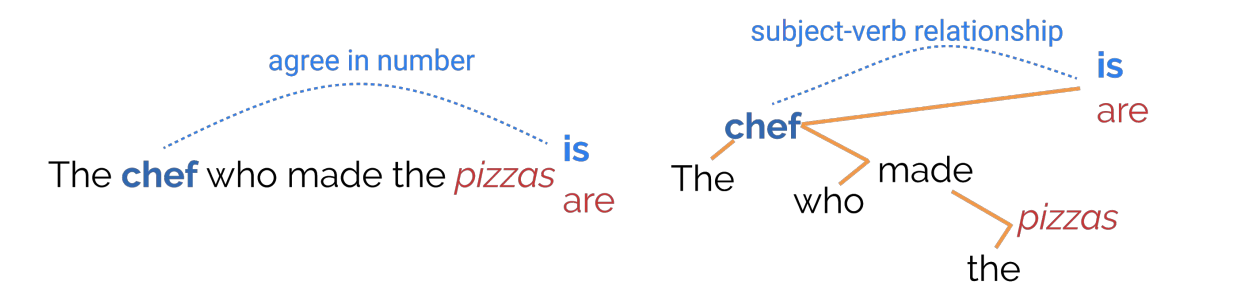
观点:英语现在时态动词的数量与主语一致。
我们如何理解语言模型(LM)中的语言行为?
一种方法:最小对立体。被接受的句子的可能性高吗?

前提:语言模型应该给可接受的句子分配更高的概率。
问提:LSTM语言模型如何使用其上下文?
方法:删除测试集比较长的上下文,或用较长的单词替换它们。评估LM困惑度是否改变。
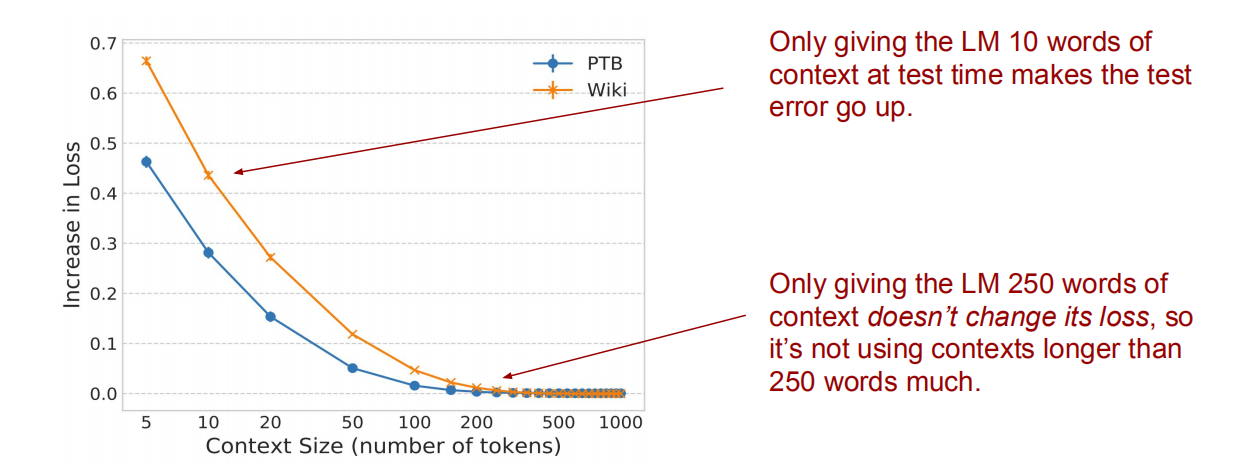
如上图所示,当长度在50以上时,困惑度变化不大,说明当前词的上下文超过50个词时,LSTM不再起作用,也即是词袋大小为50左右。
仔细的消融研究和结构修改
问题:关于我的网络结构设计,什么是必要的,甚至是好的?
方法:通过有针对性地改变模型中的结构,观察验证准确性。

如上图,通过改变transformer层网络的self-attention和feed-forward的位置,观察困惑度的变化。
分析内在可解释的架构
有些架构具有便于检查的组件,例如Bert中我们可以对多头注意力中的每一个注意力进行描述和探究。
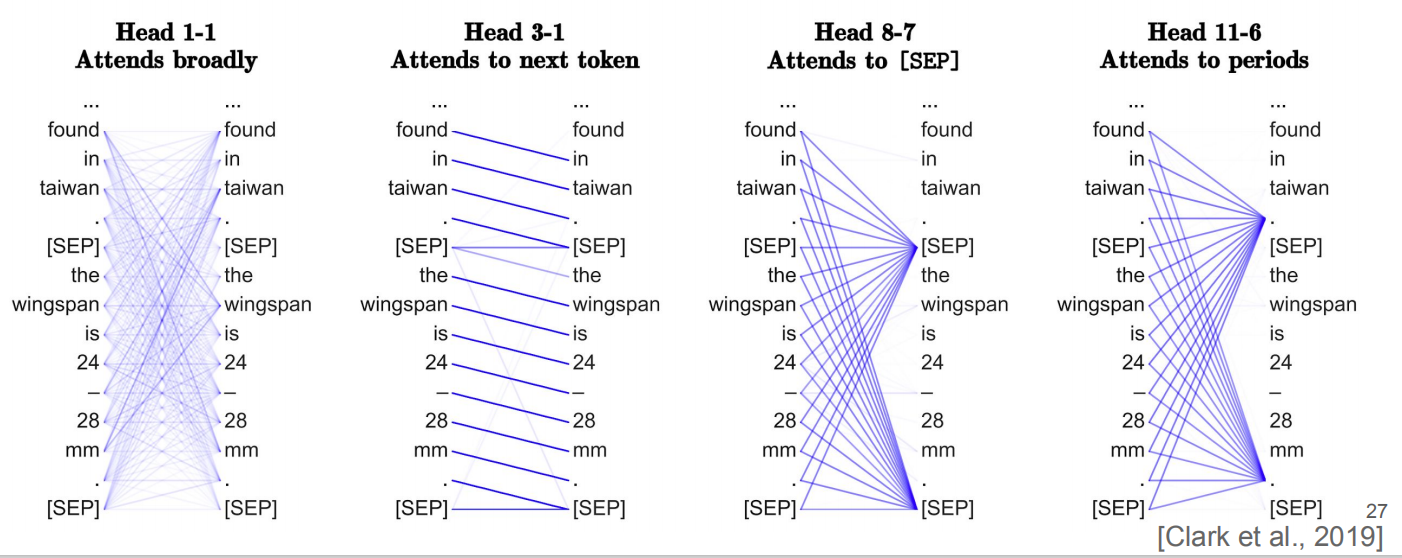
打破NLP模式
提问:我们的模型对于输入中的无害变化是否稳健?即鲁棒性如何?
在这种情况下,我们所说的健壮是指它们的输出不会改变。

如上图中的QA模型,一开始模型预测了正确答案John Elway,但是添加了一些不相关的句子在文章中之后预测发生了错误,所以这个模型无法工作。
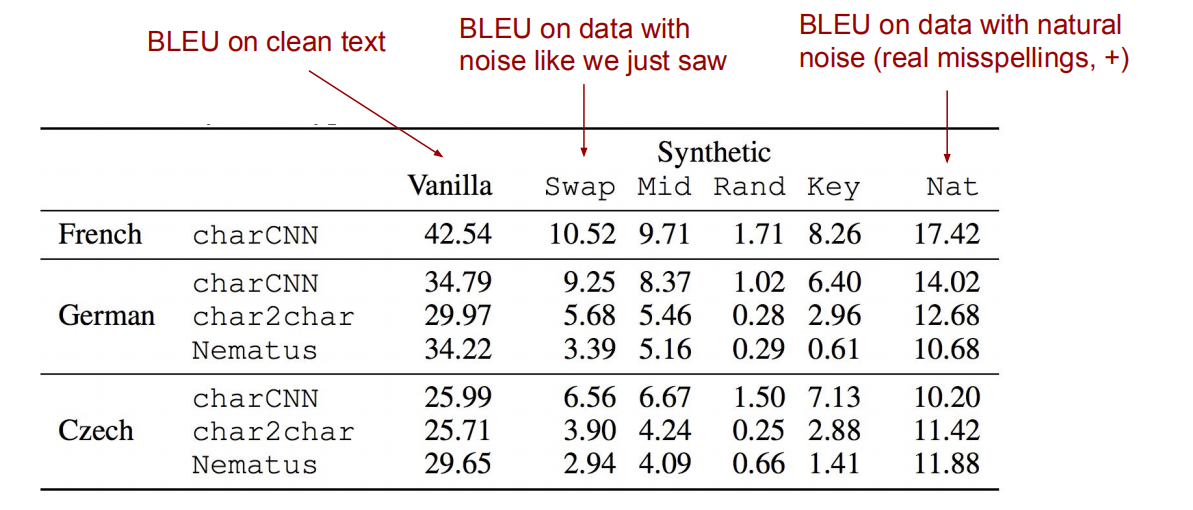
我们的模型对输入中的拼写错误或顺序调换等干扰是否健壮?从上图可以看到模型对这些都很敏感,无法获得很好的效果。
使用监督方法分析表示
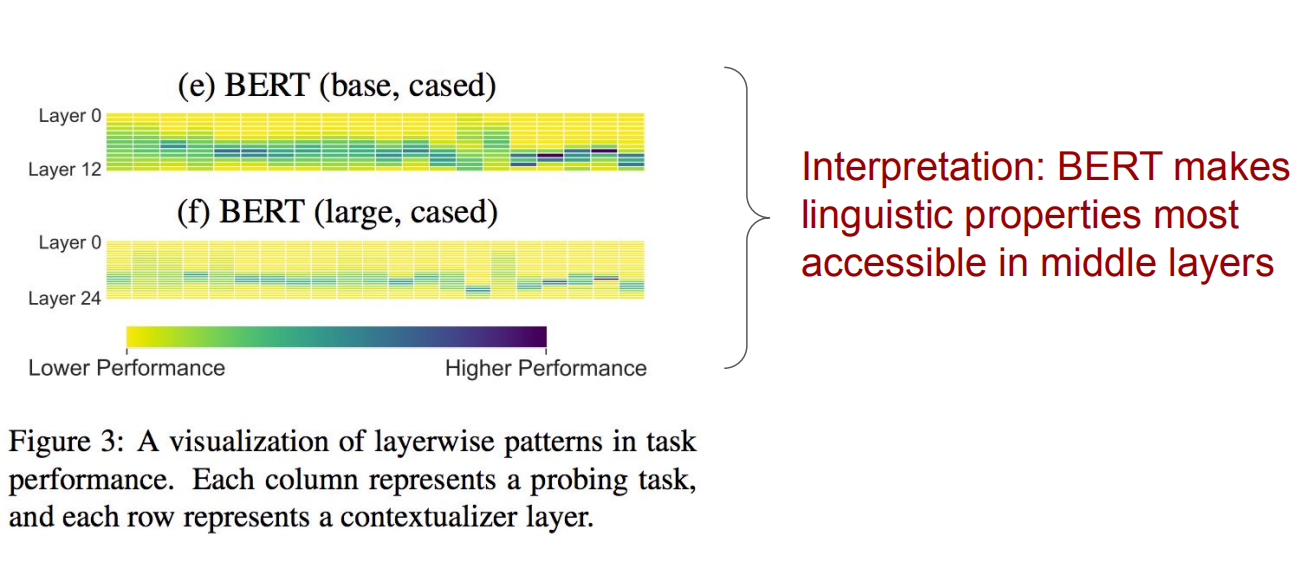
由上图可以看到,有时候,Bert的中间层可以取得更好的效果。
研究中的综合见解
神经模型是复杂的,令人着迷的东西,我们目前还不了解,但我们正在进步,以更好地了解它们。
- 了解模型在特定现象上的行为;
- 了解模型从主题或任务中学到的知识;
- 了解看似无害的输入变化却使得模型失效;
- 还有很多其他事情,每天都在更新。