
成分句法分析
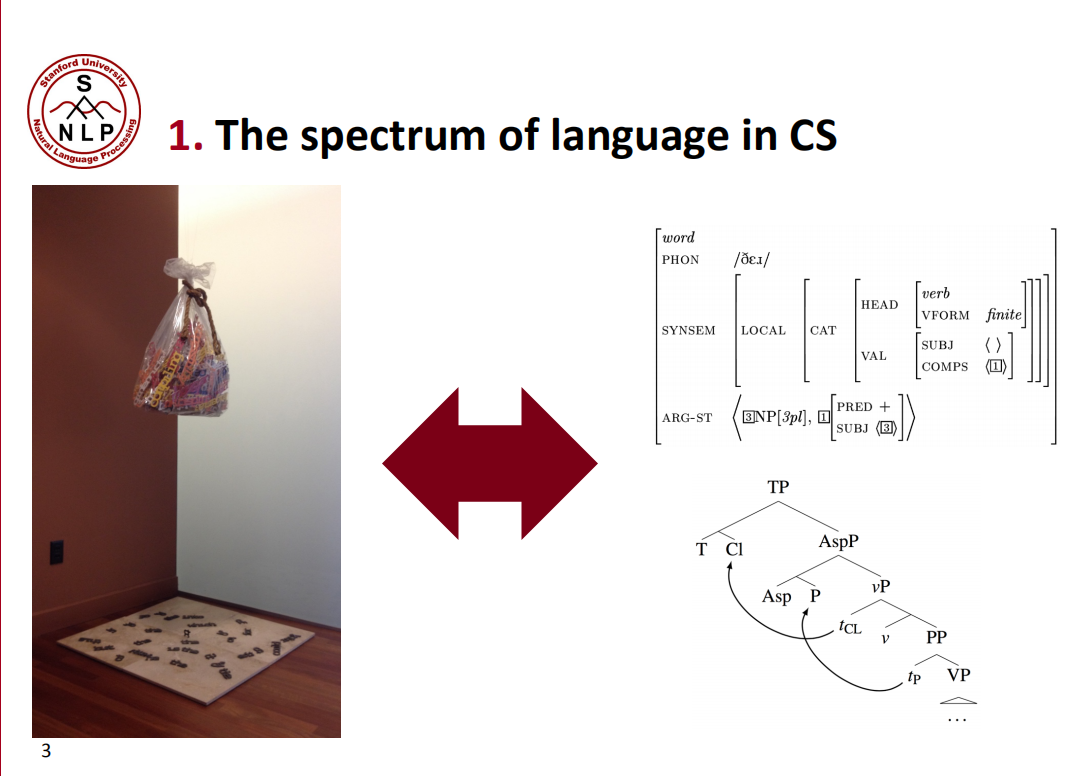
CS理解语言有两个极端,一个就是词袋模型,它把句子中的每个词都完全独立的提取出来,不考虑词和词之间关系;另外一个就是严格的成分句法分析,知道每个词在句子中充当的角色和句子里面的依赖关系,通过这种能力,我们可以通过了解较小的部分来获得更大的事物的表达。
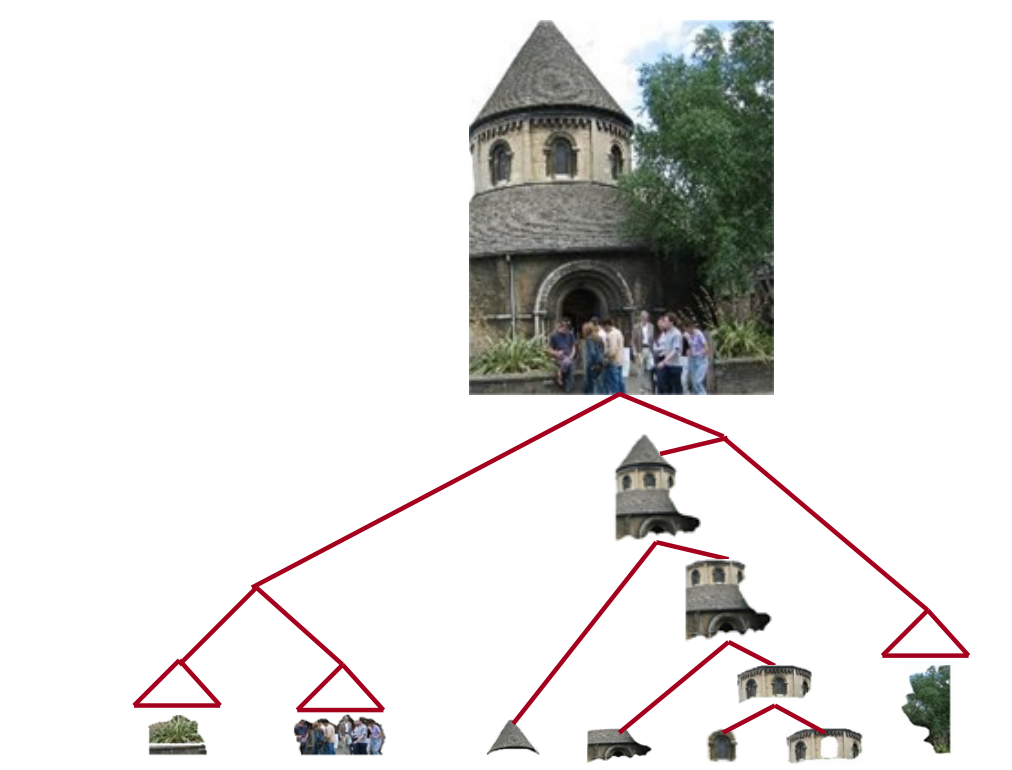
我们可以建立单词->短语->句子的递归关系,比如短的名词短语NP可以组成长的NP,一级一级往上抽象,形成一个树形的句子成分结构。把一个句子转换为这样一个树形结构的过程就是成分句法分析的过程。
树递归神经网络
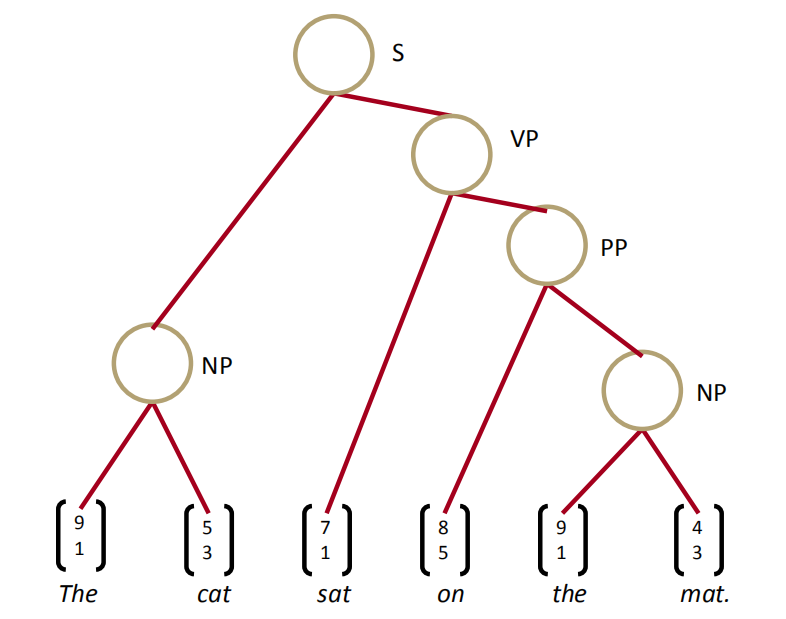
对于The cat sat on the mat.这个句子我们怎么建立一颗基于成分句法的树呢?
构建树递归神经网络
一个比较简单的办法是使用贪心算法,对于任意相邻的两个词,它们可能组合成一个新的短语表达一个更完整的含义。我们可以对所有相邻的两个词的词向量,输入到一个神经网络中,算出它们能组合成一个新的含义(新词)的概率(打分),以及这个新词的词向量。
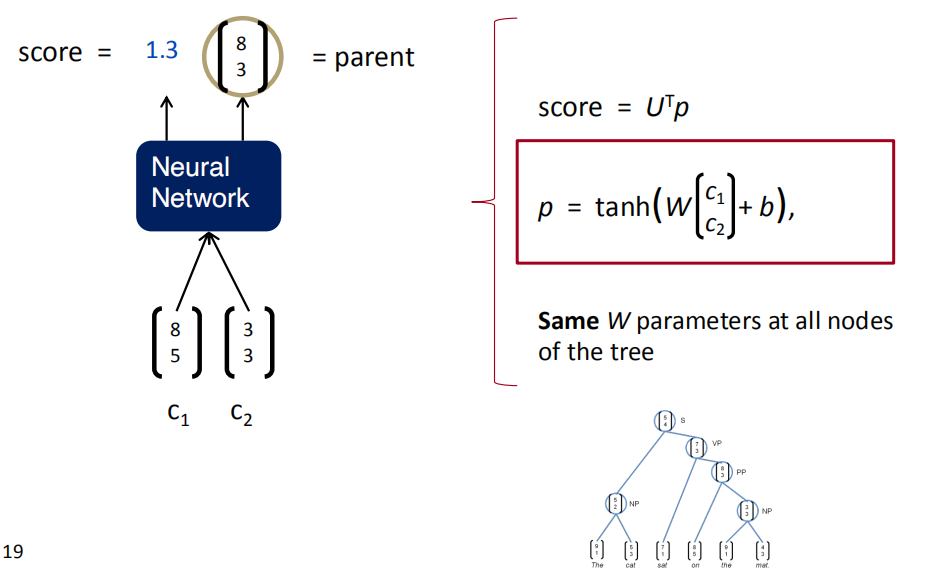
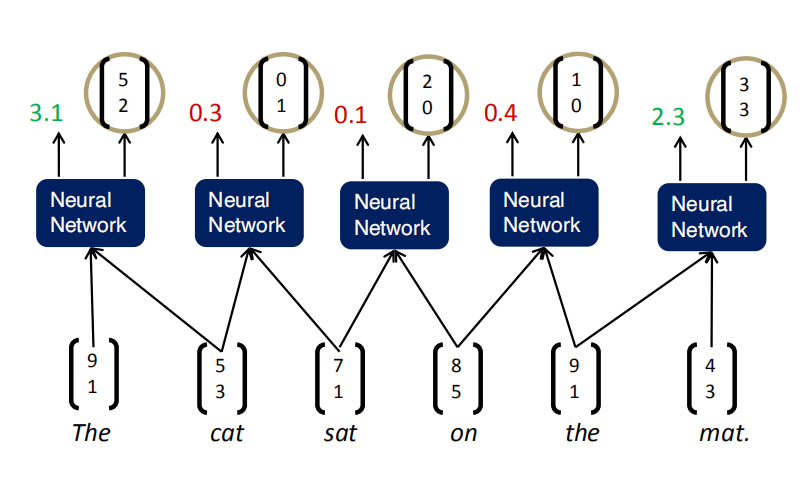
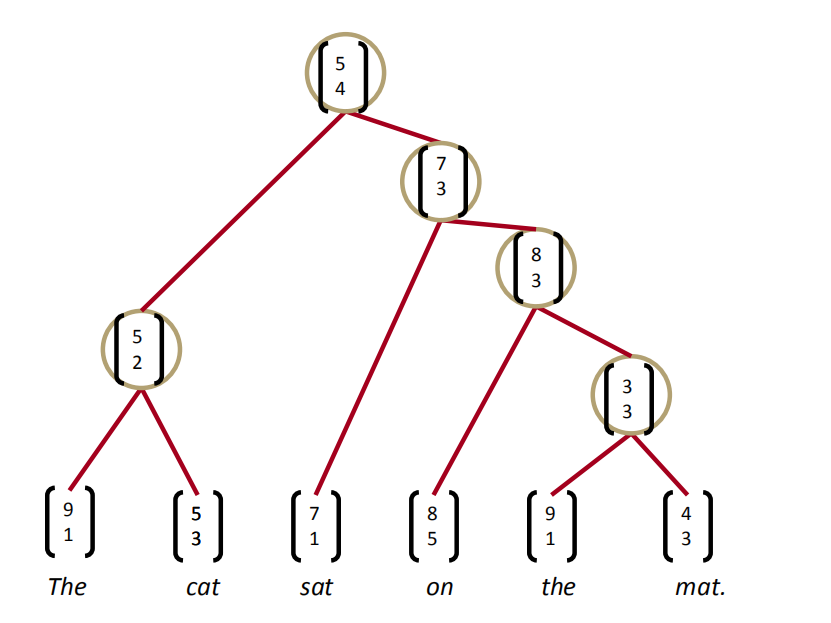
在所有组合中取打分最高的组合,把这个组合确定下来。比如下图中,The和cat组合后新的词的打分是最高分3.1,所以第一步把The cat组合起来,形成的新词的词向量是$[5,2]$。于是,就用$[5,2]$代替原来的The和cat,成为一个新词,和剩余的sat、on、the、mat.组成一个新的句子,再重复刚才的操作,直到建成一棵树,得到根节点。通过这种方法构建了一棵TreeRNN,训练的过程也是误差反向传播,求导。
树递归神经网络和循环神经网络
- 递归神经网络需要一个树结构
- 循环神经网络不能在没有前缀上下文的情况下捕捉短语,并且经常在最终的向量中过度捕捉最后一个单词
依据最大边距解析
树的得分是通过每个节点的解析决策得分的总和来计算的,其中$x$是句子,$y$是解析树:
类似于最大边距解析(Taskar et al.2004),一个受监督的最大边际目标
损失$\triangle(y,y_i)$惩罚所有不正确的决策
- 结构搜索$A(x)$是贪婪的
图片解析
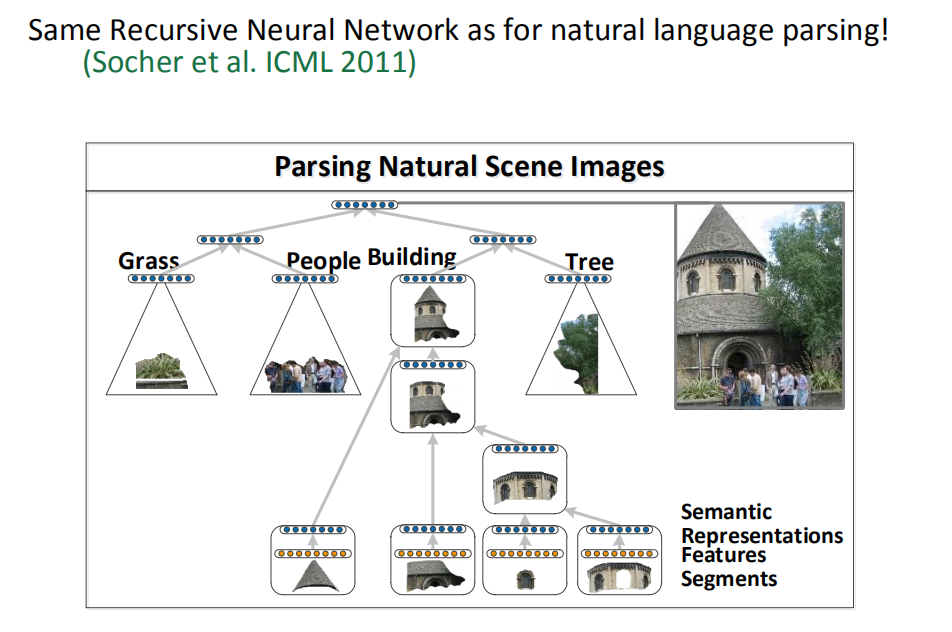
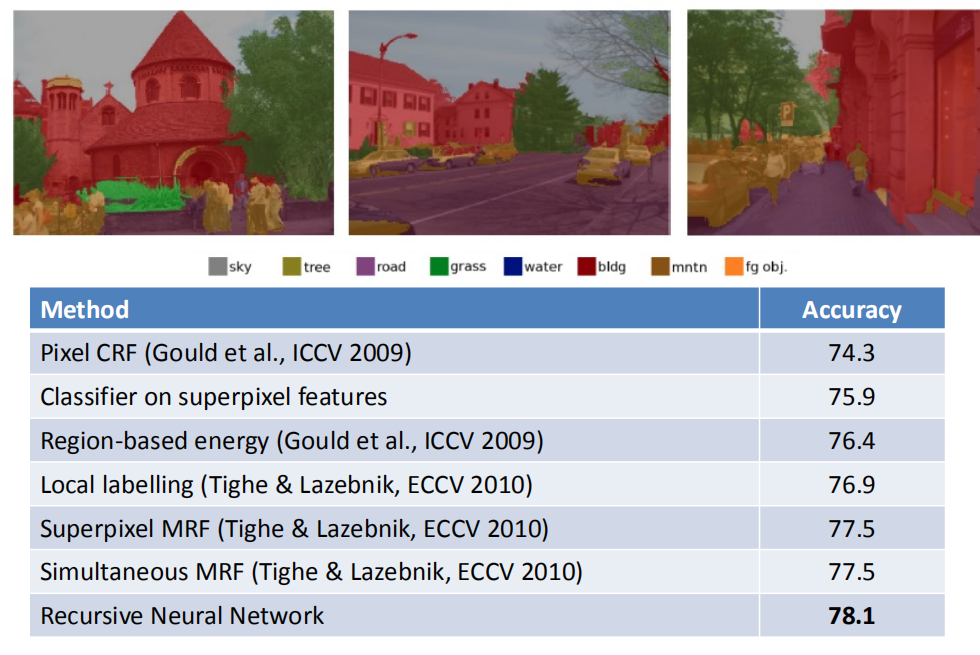
和语言解析一样,场景图像的含义也是较小区域的函数定义,这些小区域间相互组合和作用,整幅场景图片的分解也可以使用TreeRNN来完成。

对TreeRNN的改进
依句法展开的RNN(Syntactically Untied RNN)
单层RNN中的讨论太粗糙,用同一个W就想将名词短语,动词短语,甚至将两者结合在一起训练的模型,明显有问题。毕竟在一个任务中最优的W,不太可能在其他任务中表现同样出色,这就引出了SU-RNN。即,对不同的任务,使用不同的W。虽然SU-RNN增加了W的学习数目和难度,它对性能的提升,让困难变得微不足道。
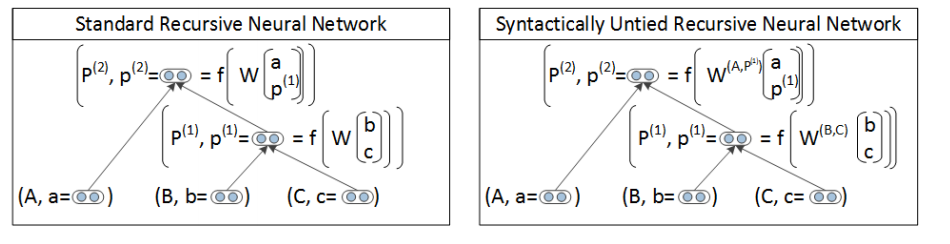
用相同的值初始化W,即默认输入的两个词向量同等重要。但SU-RNN能够通过训练时,对矩阵的旋转和缩放,逐渐学习到哪个词更重要。比如,定语+名词的组合(“The cat”和”A man”),显然名词更重要,SU-RNN能自动学习到。
如果我们想近义替换句子中的某个单词,SU-RNN依然不够优秀。比如,副词“very”通常表达“非常”的强调含义,我们不能仅依靠线性插值就找到一个词向量,并且用它去强调其他的词向量。因此,我们必须引入词向量间的乘法操作,即“词矩阵”(word matrices)和“仿射变换的乘方公式”(Quadratic equation over the typical Affine)。
矩阵向量的RNN(Matrix-Vector RNN)
我们同时使用词向量和“词矩阵”来表达单词。因此,“very”不仅拥有$d$维词向量$v_{very}$ ,还拥有一个$d*d$维的词矩阵$V_{very}$ 。这样,我们不仅可以用向量表达单词的含义,还能用矩阵表达单词的替换能力。现在,我们可以将单词a和b分别与矩阵A和B相乘,得到Aa和Bb向量。接着,将2个向量平铺展开成向量x,输入到RNN中进行训练。
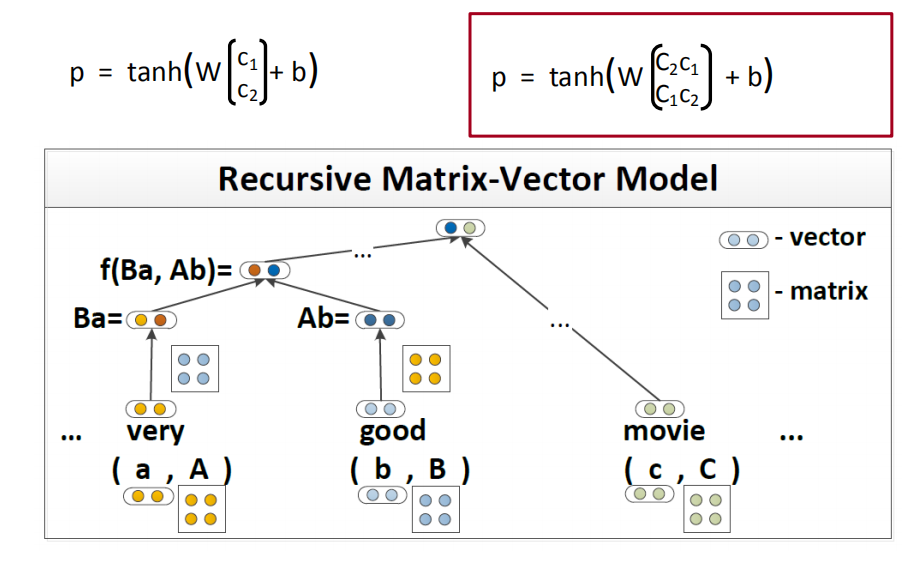
$V_{very}$矩阵可以放大任何一个含义相近的词到一定程度以表达“非常”的强调。因此,当任何一个词向量出现在我们的特征空间中,我们都能找到一个方式去替代它。
同样,MV-RNN也并不完美:
- 当我们在表达正面含义的时候,可能会有一个词,能把它变成完全负面的意思。这时,MV-RNN并不能找到合适的方式,再把它纠正回正面含义。比如most被替换成least。
- 当我们说一些事情不是特别坏或不是特别糟糕时,MV-RNN并不能学习到not的含义,并把这类表达从负面理解成中性。
- X but Y的句式:如果X是一个负面的含义,但Y是正面的,那么整个句子应当是表达正面的意思。MV-RNN做不到这一点。
因此,我们需要一种更强力的模型表示方法来解决这3类更高级的组合问题。
递归神经张量网络(Recursive Neural Tensor Network)
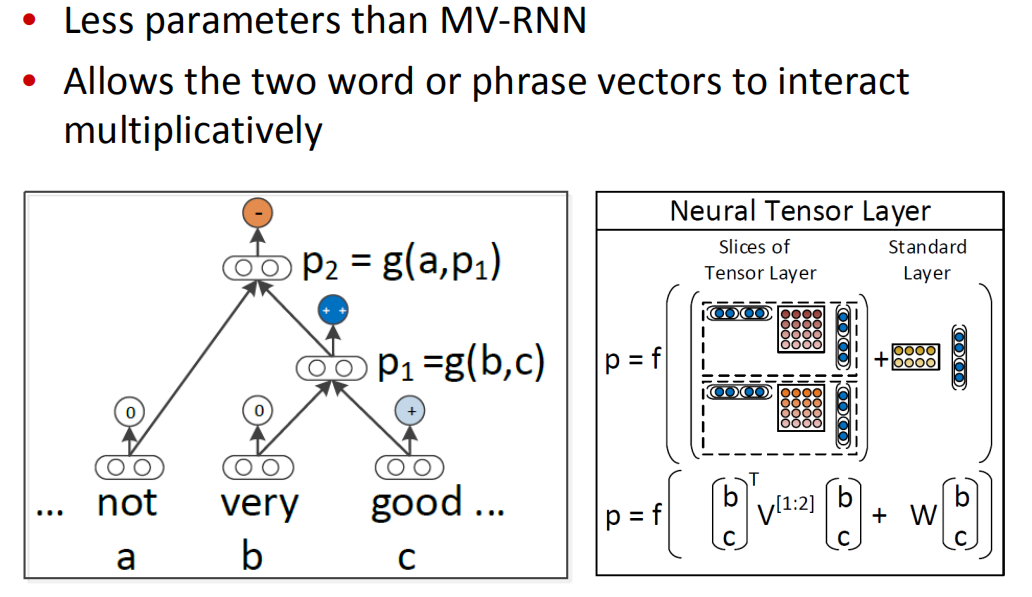
- 比MV-RNN更少的参数量
- 允许两个单词或短语向量乘法交互
在不同数据集的测试表现上,RNTN是唯一在复杂数据集上都具有成功表现的RNN模型。
后面还有很多其它的更优秀的模型,比如TreeLSTM。甚至还不需要输入语法树,比如动态卷积神经网络。