
章节1:回顾语言模型和解码算法
回顾语言模型
语言模型就是给定句子中的一部分词$(y_1,…,y_{t-1})$,要求预测下一个词$y_t$是什么:
条件语言模型不仅给了$(y_1,…,y_{t-1})$这些词,还给了$x$作为给语言模型的额外的信息:
- 在机器翻译中$x$就是源语言的句子信息;
- 自动摘要的$x$就是输入的长文;
- 对话系统的$x$就是历史对话的内容。
下图是曾经在机器翻译学到的机器翻译中的例子:
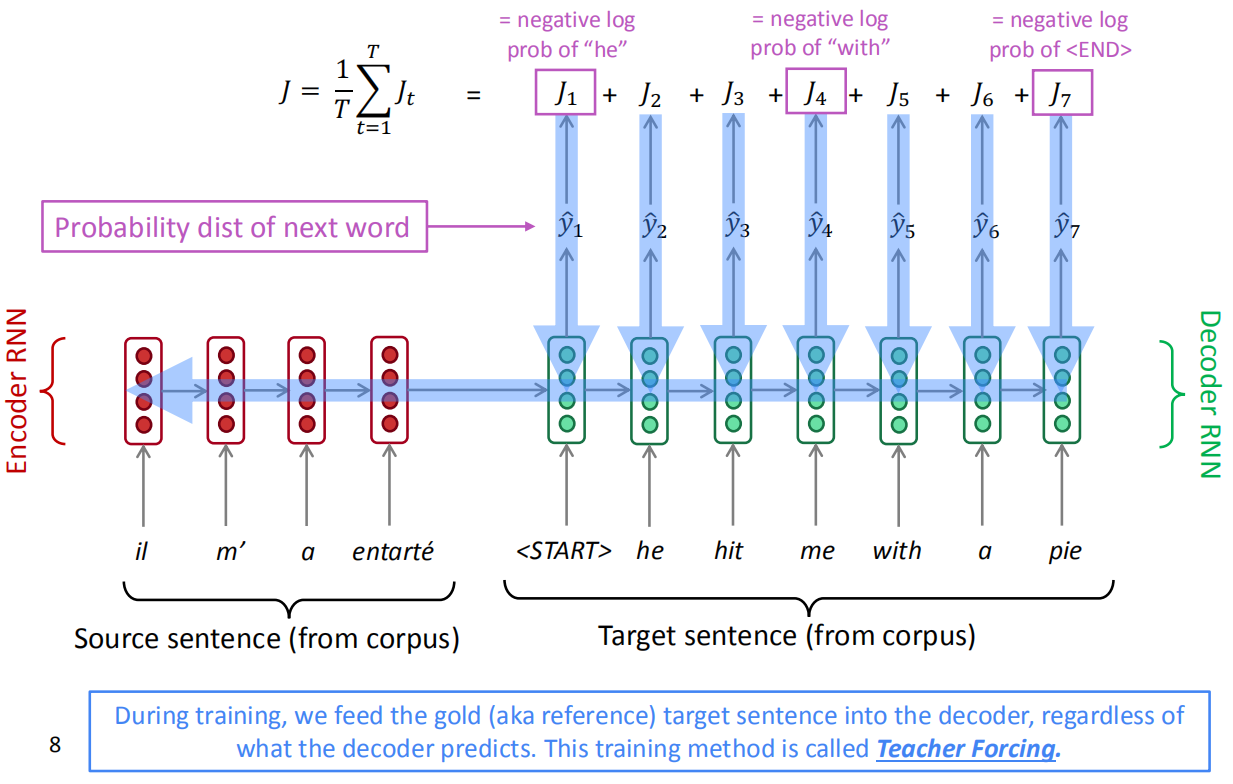
在训练期间,我们将正确的目标句子输入解码器,而不考虑解码器预测的,这种培训方法称为Teacher Forcing。即不论上一步的输出是什么,都强制给这一步输入正确的词。而如果在测试阶段,Decoder的输入是上一步的输出。
回顾解码方法
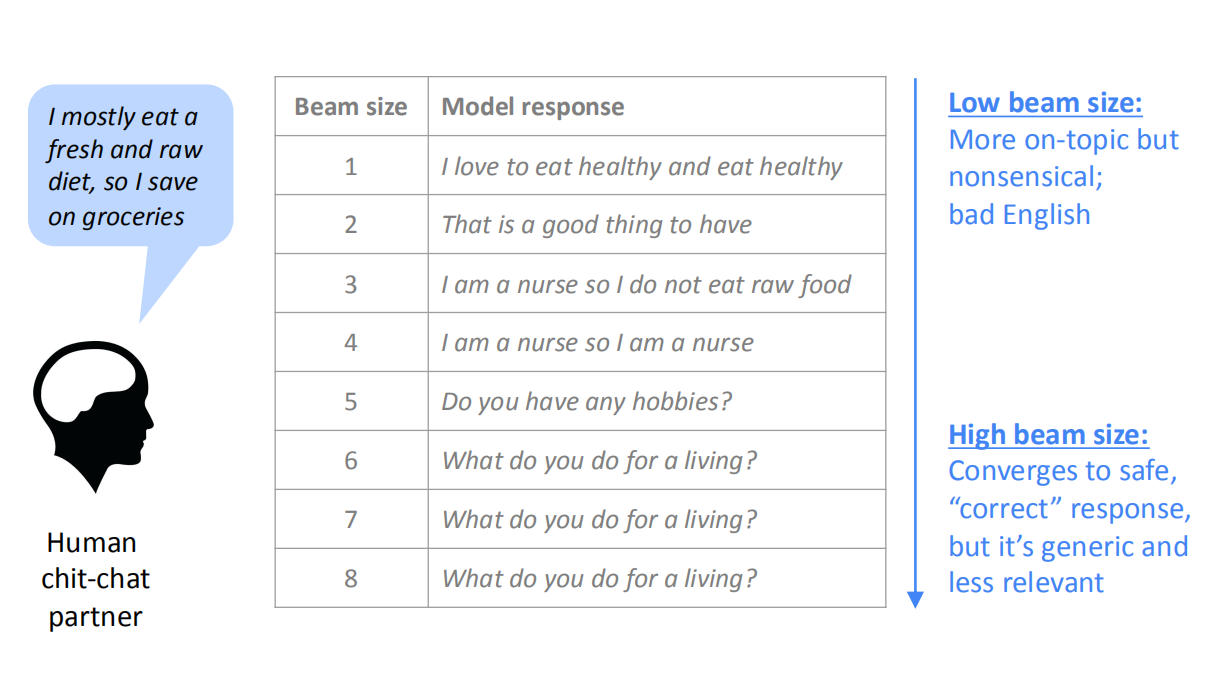
语言模型的解码有Greedy search和Beam search两种,具体可以回顾Beam search decoding,在机器对话中保留的k同的出的结果也不同,当k增大,计算量也会随之增大,对于NMT任务,k的增大会导致翻译出来的句子更短,BLEU得分更低;对于对话系统,k的增大会使得得出的句子更加的安全和“正确”,但它太通用,丢失了和问题之间相关性。如下图,当k=1时,回答和对话有点关系,但是k不停增大,句子变得正确和通用了,但是答非所问了。
除了Greedy search和Beam search两种解码算法,还有两种基于采样的解码算法。
Pure sampling在每个$t$时刻,根据softmax出来的概率分布中随机抽样获取下一个单词;Top-n sampling只在概率top-n的词中采样,相当于对Pure sampling的概率分布进行truncate。与Beam search不同得是,这种采样方法在每个时刻都只需要保留一条结果,但是采样结果又增加了结果的丰富性。

Softmax temperature是一种带温度的语言模型输出概率方法,它通过控制采样间隔时间,让概率分布变得扁平或者尖突,配合不同的解码算法,可以控制产生不同流畅度、新奇度的句子。
四种解码算法如下:

章节2:自然语言生成任务和神经网络方法的引入
摘要生成
自然语言生成任务是一类生成新文本的任务,包括机器翻译、自动摘要、对话系统、写作机器人、看图说话等。下面对其中几个任务进行简单的介绍。
如何定义自动摘要任务?自动摘要任务要求给定一段长文本$x$,生成短文本$y$,$y$能概括$x$的内容,自动摘要又分为单文档和多文档。

自动摘要有两种实现办法一种是抽取式摘要(Extractive Summarization),一种是抽象式摘要(Abstractive Summarization),前者有点像是缩写,后者使用语言模型生成新的句子作为摘要,相当于概括性重写,会更难。

在引入神经网络之前
在引入网络结构之前采用的是Extractive summarization,它是一个pipeline,类似于前网络时代的机器翻译。
- 内容选择 Content selection:选择一些句子
- 信息排序 Information ordering:为选择的句子排序
- 句子实现 Sentence realization:编辑并输出句子序列例如,简化、删除部分、修复连续性问题)
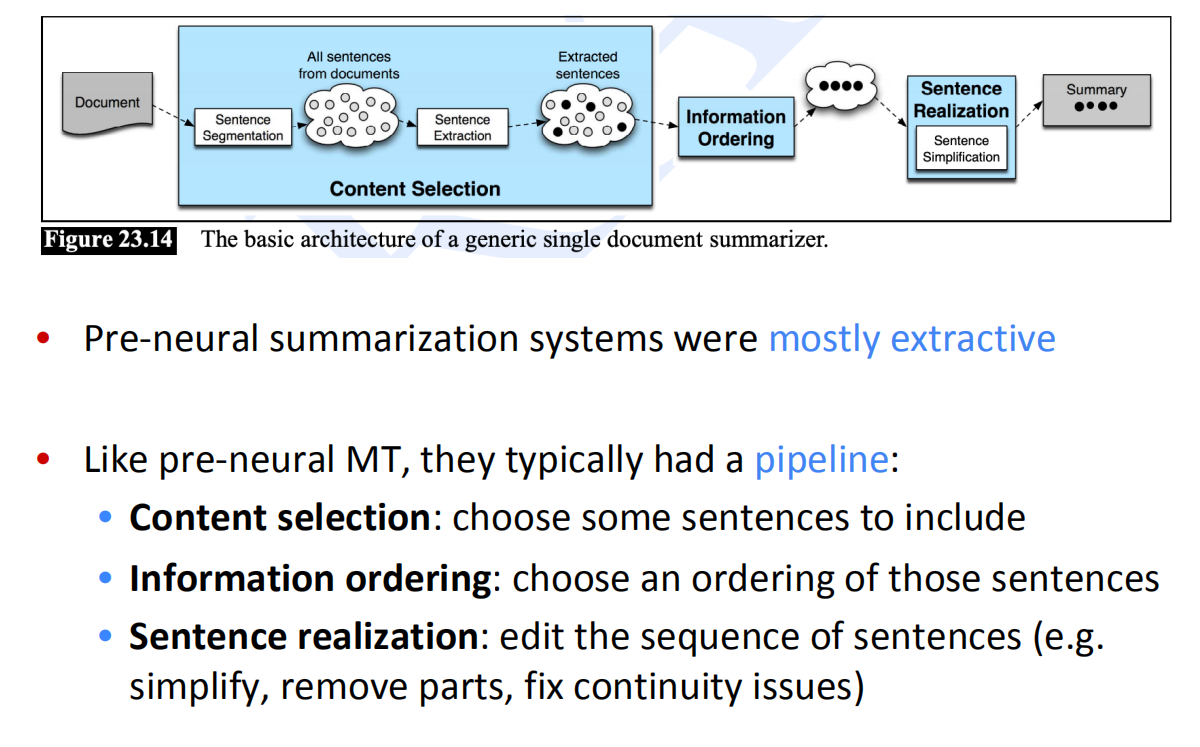
在内容选择上,有得分和图算法两种。一种是得分,比如使用tf-idf,或者使用文本出处这些特性。图算法将文档变为一组一组句子(节点),每对句子之间存在边,通过计算边的权重与句子相似度来识别图中最重要的句子。

摘要评估方法:Rouge
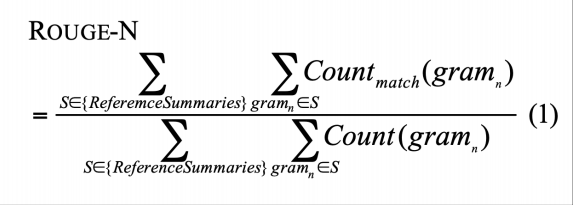
Rouge和BLEU类似,都是基于模型输出和标准答案之间的覆盖度,但是Rouge没有简洁惩罚,通常使用基于F1的版本。
ROUGE: A Package for Automatic Evaluation of Summaries, Lin, 2004
引入神经网络后(2015-现在)
把单文档摘要摘要是一项翻译任务,一般基于标准的seq2seq+attention的机器翻译方法。
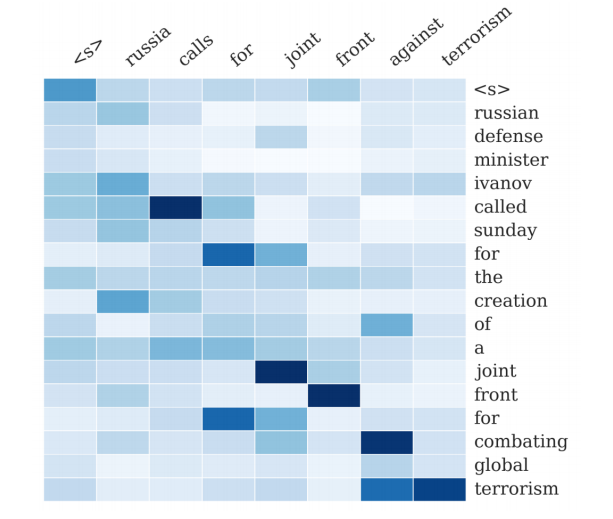
其概括如下:

A Neural Attention Model for Abstractive Sentence Summarization, Rush et al, 2015
复制机制
Seq2seq+attention systems 善于生成流畅的输出,但是不擅长正确的复制细节(如罕见字),复制机制使用注意力机制,使seq2seq系统很容易从输入复制单词和短语到输出,这有利于摘要的生成。
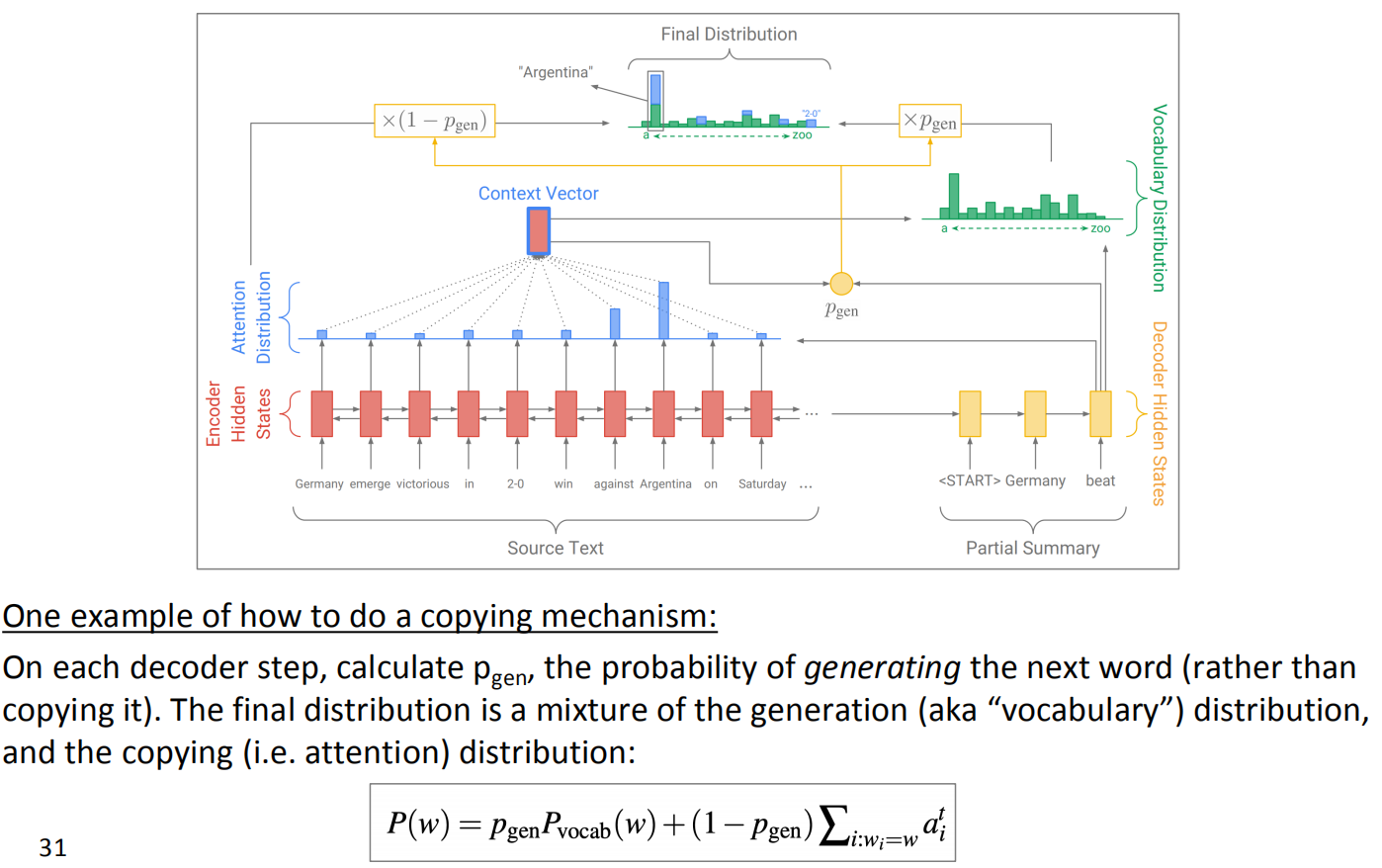
但是它也会有问题,如果复制得太多,系统就退化成抽取系统了,并且对于文档很长的情况下,复制机制缺乏对整体内容的选择机制。
Get To The Point: Summarization with Pointer-Generator Networks, See et al, 2017
选择更好的内容
如何才能让系统在全局得文档内容里面做选择?一个比较好的办法是自下而上的汇总。这种方法叫做Bottom-up,在内容选择阶段,使用一个神经序列标注模型将单词划分为包含/不包含的分类。然后在注意力阶段,让seq2seq+attention模型忽视不包含的单词。
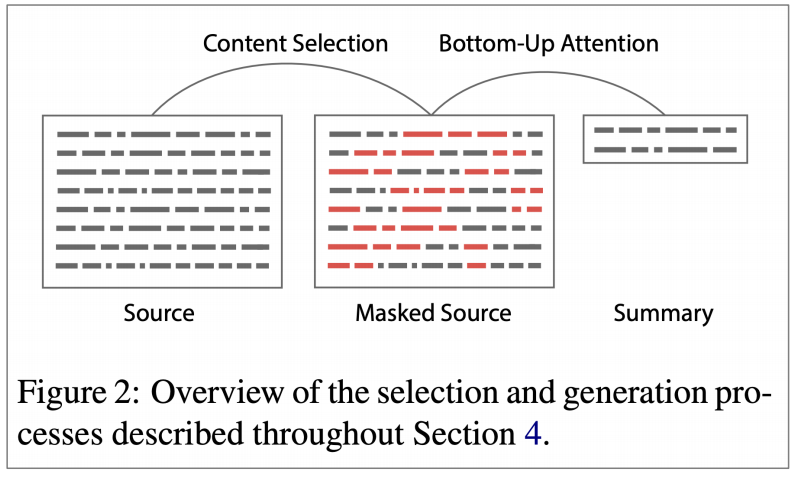
这种方法简单高效,能够对整体的文档内容更好的选择,并且模型会跳过不包含的单词选择整理包含的而单词进行组合,减少对长序列的复制。
对话系统
对话系统可以分为面向任务的对话和社会对话,前者比如说辅助客服、合作、对抗辩论,后者比如闲聊或者健康咨询方面的对话等。
前神经网络时代和后神经网络时代
神经网络之前的做法是事先设计一些问答模板,根据场景,给模板填充不同的内容。或者使用信息检索的方式,从问答库中检索问答。之后seq2seq+attention的方法被用进来。
- A Neural Conversational Model, Vinyals et al, 2015
- Neural Responding Machine for Short-Text Conversation, Shang et al, 2015
基于Seq2seq的对话系统
简单的应用标准seq2seq+attention的方法在闲聊任务中有严重的普遍缺陷:- 平淡无奇的回答
- 鸡同鸭讲的回答
- 重复回答的问题
- 缺乏上下文(不记得谈话历史)
- 缺乏一致的角色人格
针对上述问题,下文分别介绍了针对性的解决思路。
鸡同鸭讲的回答
出现这种无相关的回答主要是因为一些机器总是找那种通用性强的句子,比如“我不知道”,或者问的人突然改变了话题,机器反应不过来。
它的一个解决办法是不是去优化输入$S$到回答$T$的映射来最大化给定$S$的$T$的条件概率,而是去优化输入$S$和回复$T$之间的最大互信息Maximum Mutual Information(MMI),从而抑制模型去选择那些本来就很大概率的通用句子:
平淡无奇的回答
简单的修复包括增大Beam Search中的k值或者使用上文提到的采样算法。还可以使用条件修复,用一些额外的内容训练解码器(如抽样一些内容词并处理),或者通过既有的语料库训练一些场景对话,而不是从头生成。
重复回答的问题
可以直接在Beam Search中禁止重复n-grams,这个方法非常有效。也可以使用较复杂的方法解决,比如说在seq2seq中训练一个覆盖机制,可以防止注意力机制多次注意相同的单词。也可以把不重复当作一种训练目标。
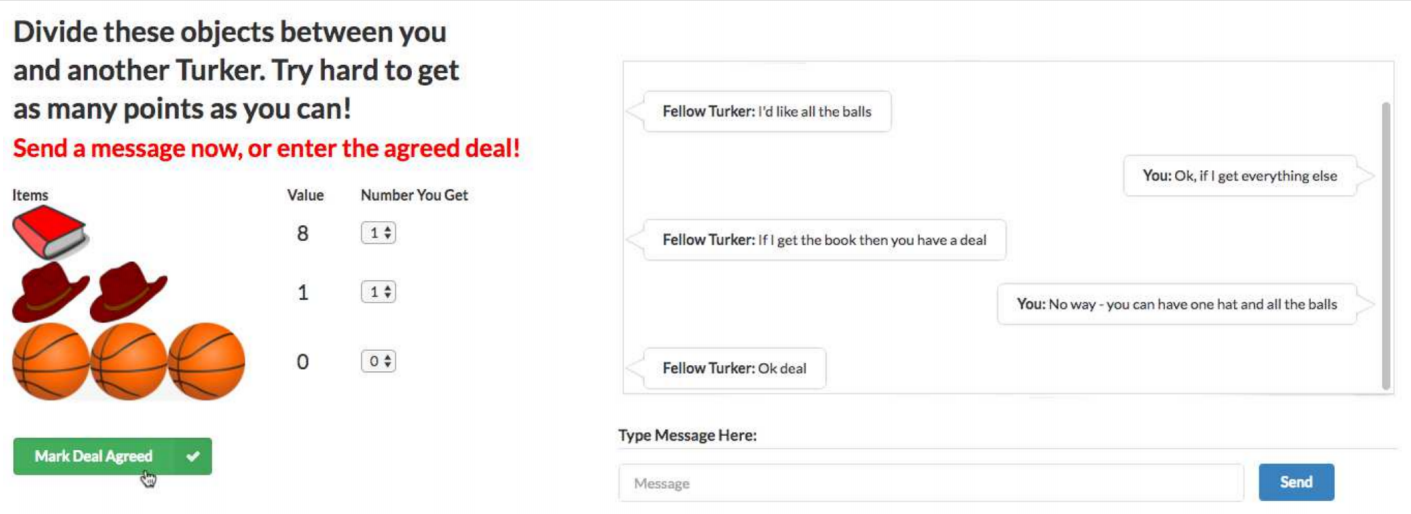
协商对话
- 两个代理协商谈判对话(通过自然语言)如何分配一组项目
- 代理对项目有不同的估值函数
- 代理人会一直交谈直到达成协议
对话问答:CoQA
这是一个来自斯坦福NLP的新数据集,它的任务是回答关于以一段对话为上下文的文本的问题,答案必须是要进行摘要的描述而不是简单的复制,所以它类既包括阅读理解任务,也包括对话任务。

CoQA: a Conversational Question Answering Challenge, Reddy et al, 2018
故事生成
简介
故事生成包括:
- 给定图像生成的故事情节段落
- 给定一个简短的写作提示生成一个故事
- 给定迄今为止的故事,生成故事的下一个句子(故事续写)
由语言模型生成的故事听起来很流畅但是故事内容不连续,无意义。因为讲好一个故事需要知道事件和故事的因果关系,故事里面的人物关系、故事发生的场景、叙事的结构和叙事的原则。

事件到事件(Event2event)的故事生成
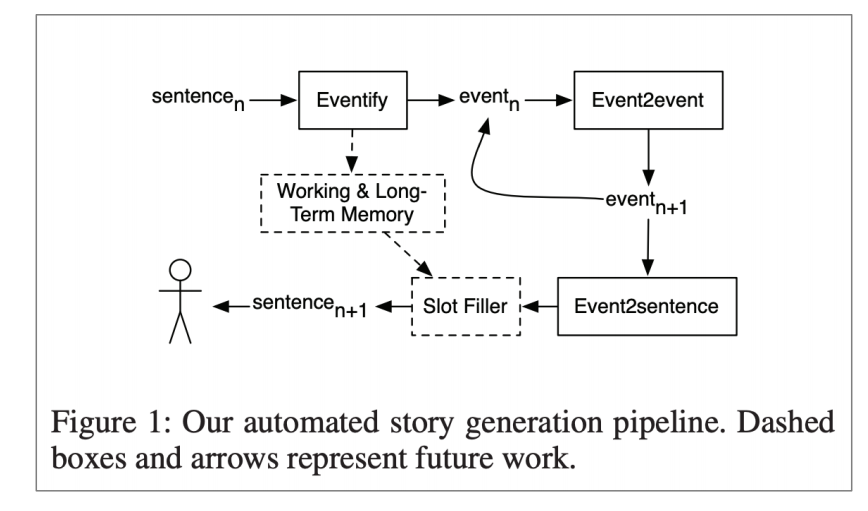
Event Representations for Automated Story Generation with Deep Neural Nets, Martin et al, 2018
有结构的故事生成
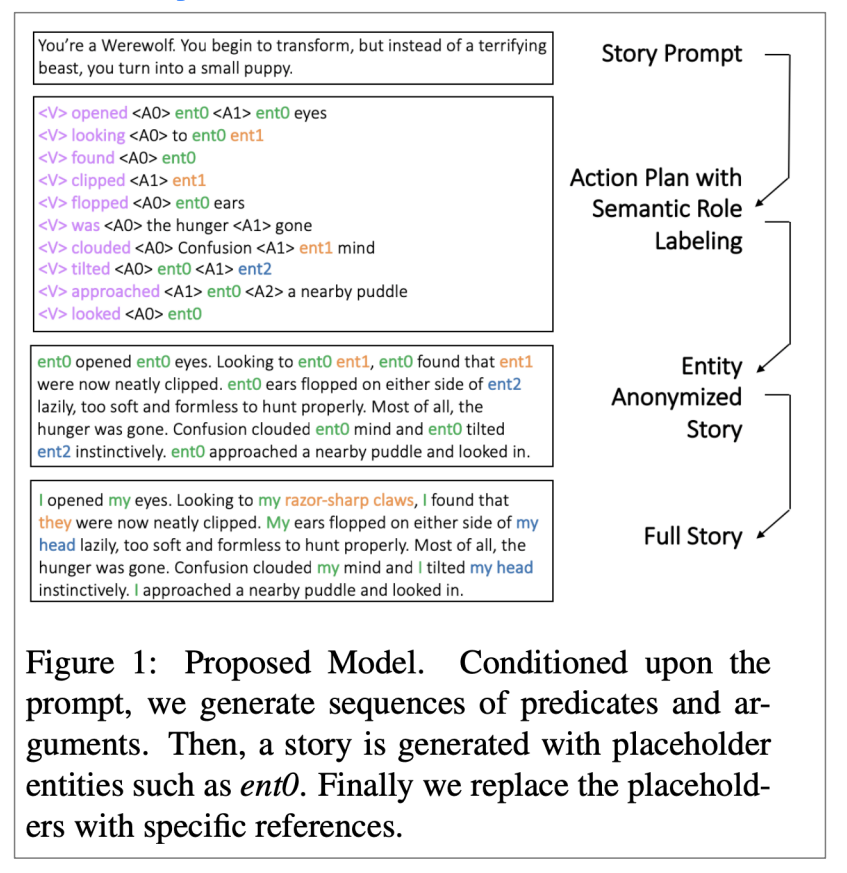
Strategies for Structuring Story Generation, Fan et al, 2019
诗词生成:Hafez
它的主要思想是使用一个有限状态受体(FSA)来定义所有可能的序列,服从希望满足的节奏约束,然后使用FSA约束RNN-LM的输出得到约束状态下的诗词。
莎士比亚的诗:
有结构的故事生成

- 莎士比亚的十四行诗是14行的抑扬格五音步韵律
- 所以莎士比亚的十四行诗的FSA有$((01)^5)^{14}$种状态
- 在做Beam Search的时候只搜索满足FSA假设的状态
Generating Topical Poetry, Ghazvininejad et al, 2016
Hafez: an Interactive Poetry Generation System, Ghazvininejad et al, 2017
其流程如下:
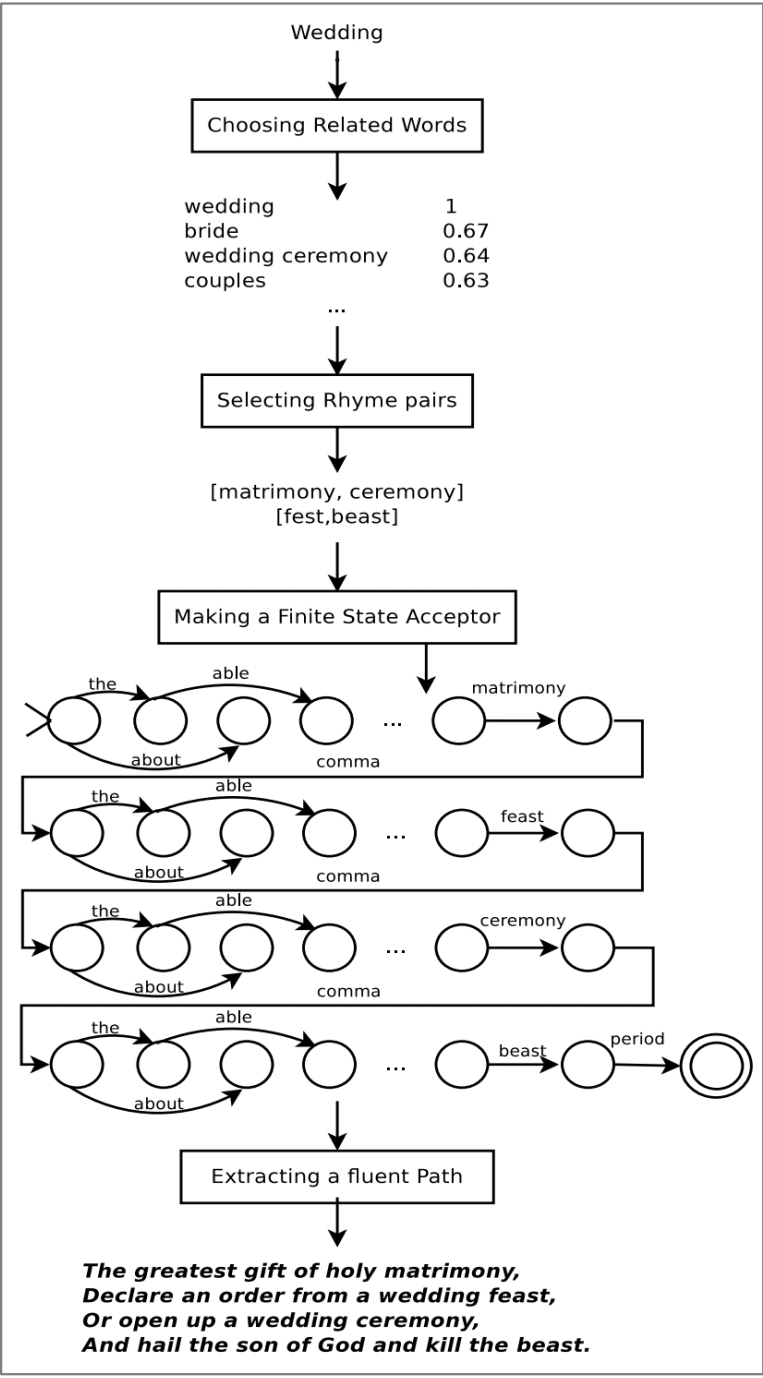
- 用户提供主题字
- 得到一个与主题相关的词的集合
- 识别局部词语押韵
- 使用受制于FSA的RNN-LM生成这首诗
- RNN-LM向后(自右向左),因为每一行的最后一个词是固定的韵脚。
在后续的一篇论文中,作者制作了系统交互和用户可控:在Beam Search中,增大具有期望特征的单词的分数。
诗词生成:深度-莎士比亚
这是一种端到端的多任务学习诗歌生成方法。它具有三个组件分别是语言模型、五步格诗的模型和韵律模型。
作者发现诗歌的格律和押韵是相对容易的,但生成的诗歌上有些缺乏“情感和可读性”
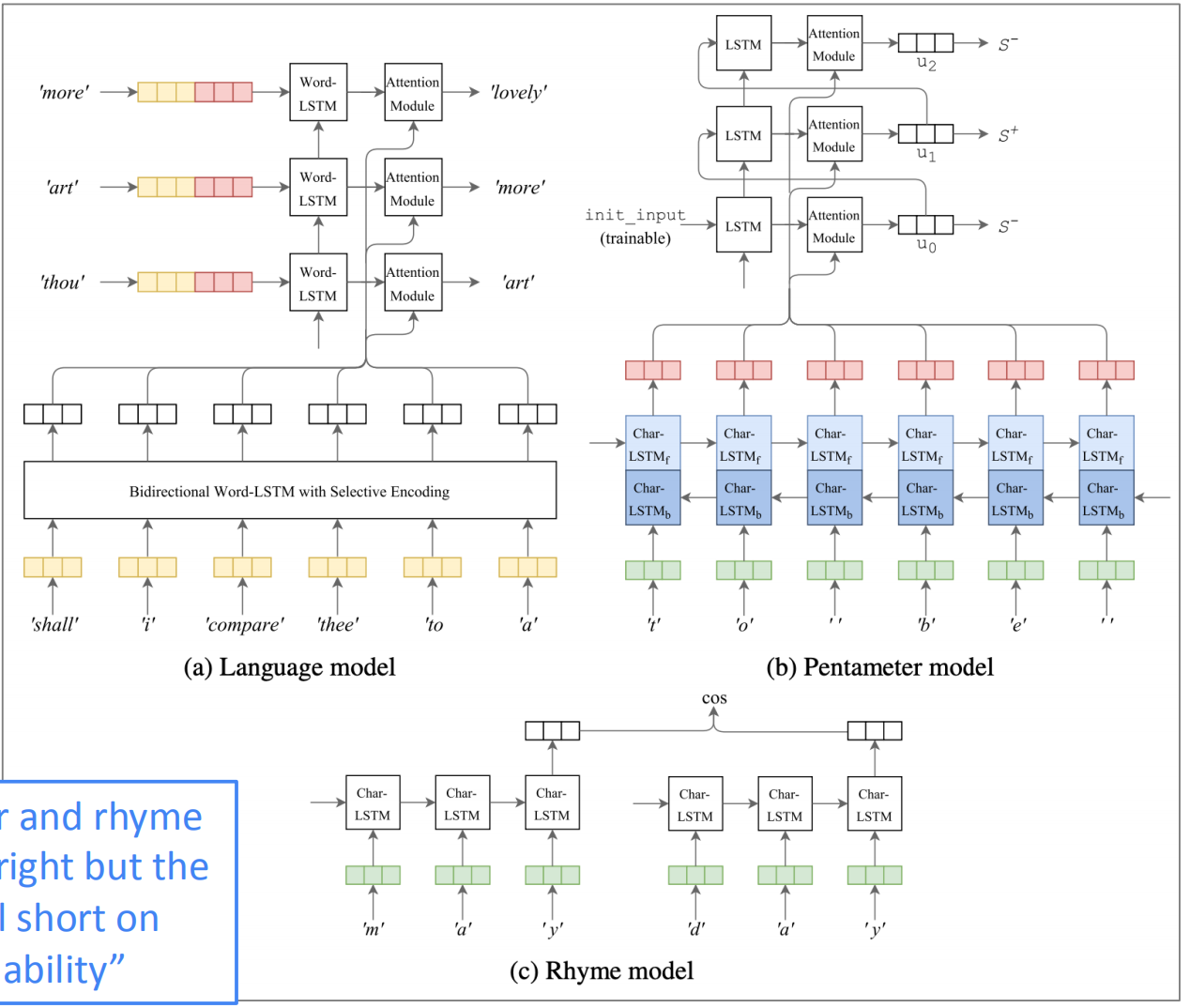
Deep-speare: A joint neural model of poetic language, meter and rhyme, Lau et al, 2018
非自回归模型在机器翻译中的应用
这是一种非自回归模型,它的意义在于它不是根据之前的每个单词,从左到右产生翻译,而是并行的翻译,所以它的翻译效率快。其架构也是基于Transformer,但是它的解码器也可以并行输出结果。
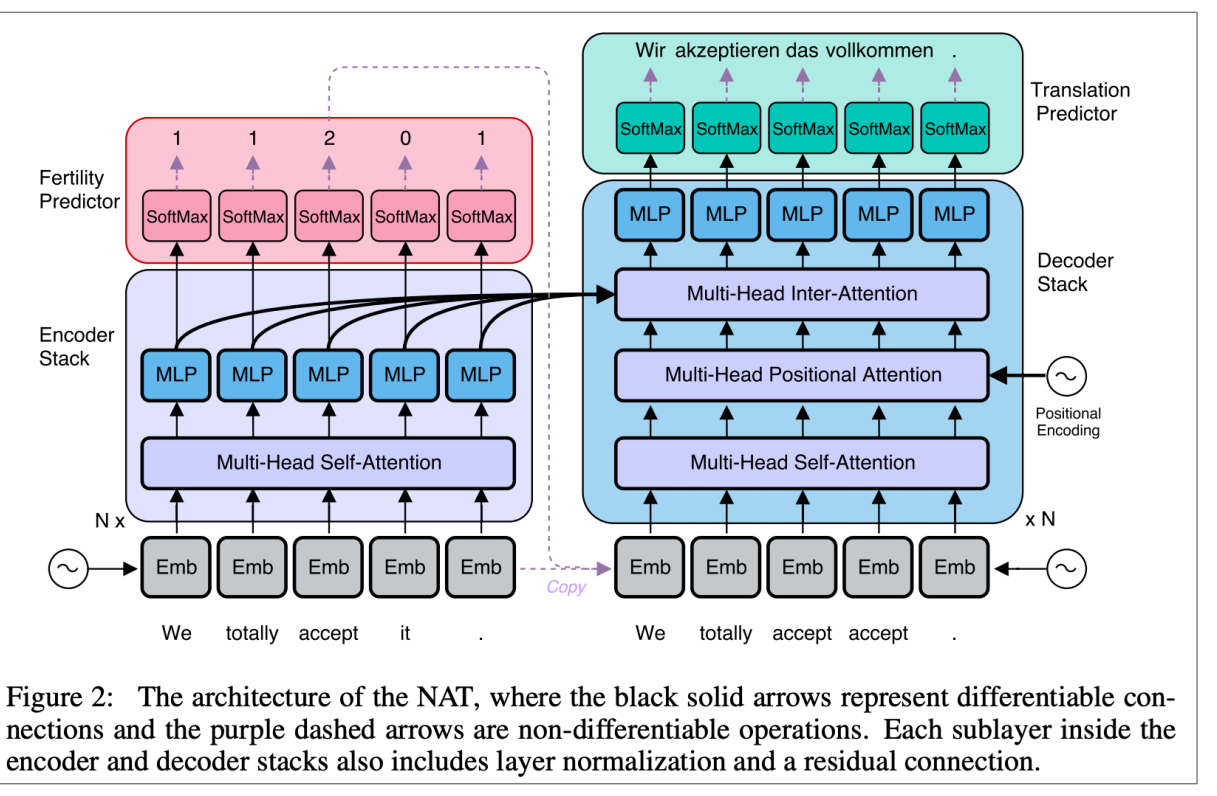
Non-Autoregressive Neural Machine Translation, Gu et al, 2018
章节3:自然语言生成任务的评估
目前对自然语言生成模型没有特别好的评价指标,BLEU和ROUGE都是基于n-gram和标准答案间算重叠率来计算,ROUGE对抽取型的摘要抽取结果打分好一些,而抽象型的摘要生成由于答案具有主观性导致n-gram的overlap较低,没有办法评估模型的好坏,对话系统就更加无法评价了。困惑度可以用来衡量语言模型的好坏,但是无法衡量NLG的好坏,比如这个句子很通顺,但是生成句子与文档文不对题,那么它在摘要这块评分就会很低。还有种办法是用词向量,原来的基于n-gram的重叠方法只是字面上的意义,而词向量的办法可以深层次的考察生成的句子的含义是否能够表达原文,它的想法是比较生成文本中的词和标准答案的词向量是否相近。但是这样办法判断出来的相似度和人判断的相似度的相关性依然不是特别好。
目前来看NLG这块没有一个固定的指标,评价它可以关注一些细分的指标,比如流畅度、多样性、相关性等。

章节4:自然语言生成的研究思路,目前的趋势和它的未来
- 融合离散潜在参数。
- 在句子生成的时候可以并行的生成一句话,而不是通过自回归的方式,比方说Transformer,它在编码端已经做到了并行,未来在解码端也可能会出现并行输出。
- 除了Teacher forcing的训练方法,可能会出现单步中将整个句子做为训练的方法,而不仅仅是现在基于词级别的办法往模型喂语料。