
From RNNs to Convolutional Neural Nets
关于CNN的基础知识可以在很多地方学习,这篇文章主要学习卷积在NLP中的用法。
A 1D convolution for text
首先,我们来看下最简单的单通道下,卷积核kernal=3的情况,怎么计算结果,假设有一个句子:tentative deal reached to keep government open,我们把这句话每一个单词使用维度为4的向量进行表征:
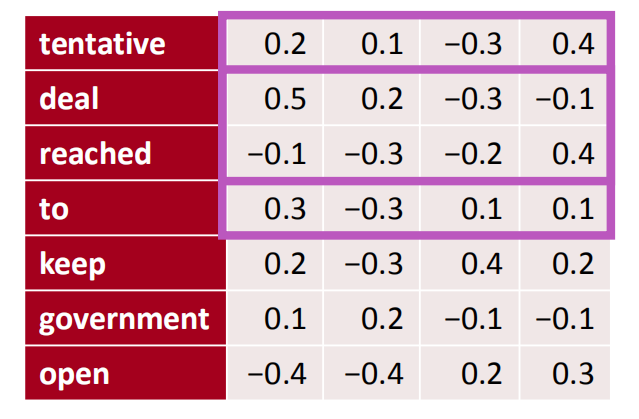
接下来使用一个kernal为3的卷积核对其在每一个维度的纵向上进行卷积操作:

那么它的计算方式如下,首先对tentative、deal、reached(t,d,r)进行卷积,卷积过程:
在第一维度:
在第二维度:
在第三维度:
在第四维度:
四个维度加起来组成第一步卷积结果:
因为卷积步长为1,因此接下来对deal、reached、to(d,r,t)同样的方法操作,依次类推得出最后的结果:
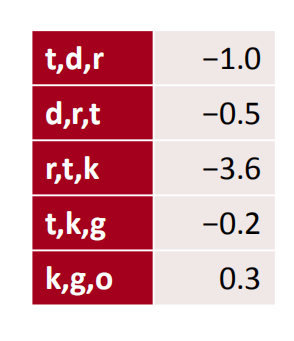
1D convolution for text with padding
当出现有padding的时候,padding的维度的值都为0,卷积的方法和上述一样:
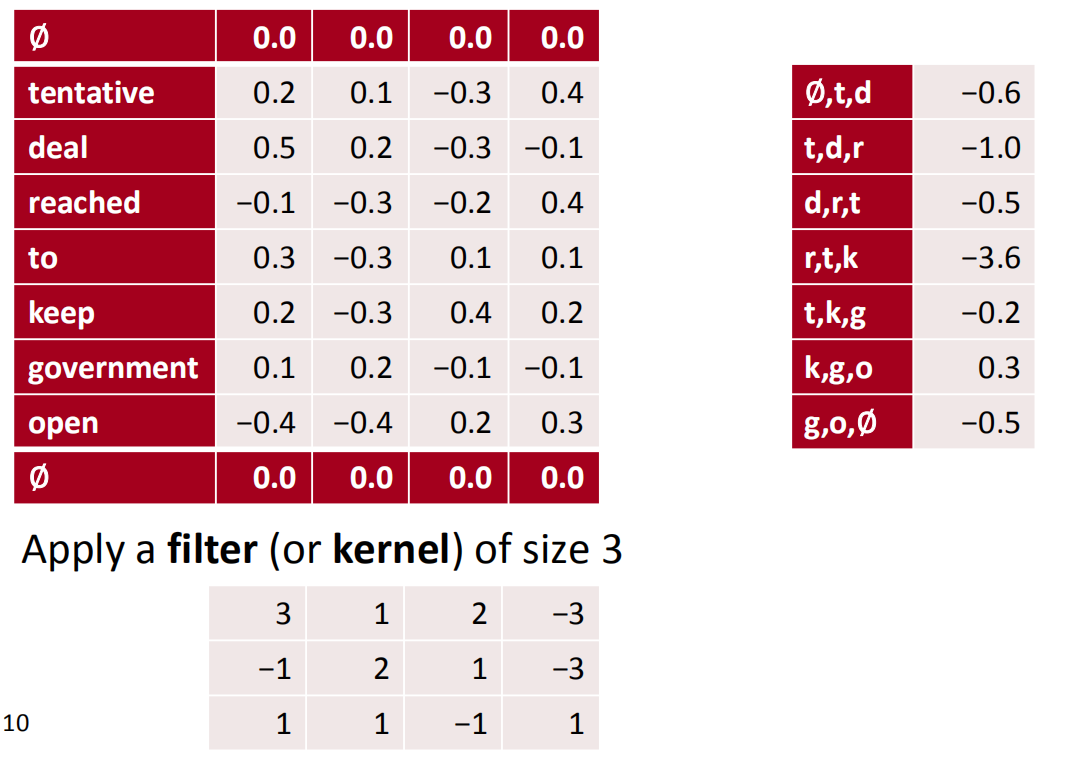
3 channel 1D convolution with padding = 1
如果是多通道的(此处为3通道),那么就会对应多个卷积核,操作方法其实跟上述一样,只不过求的时候分别求出3个卷积核的结果,然后输出就是三列(对应3个通道)
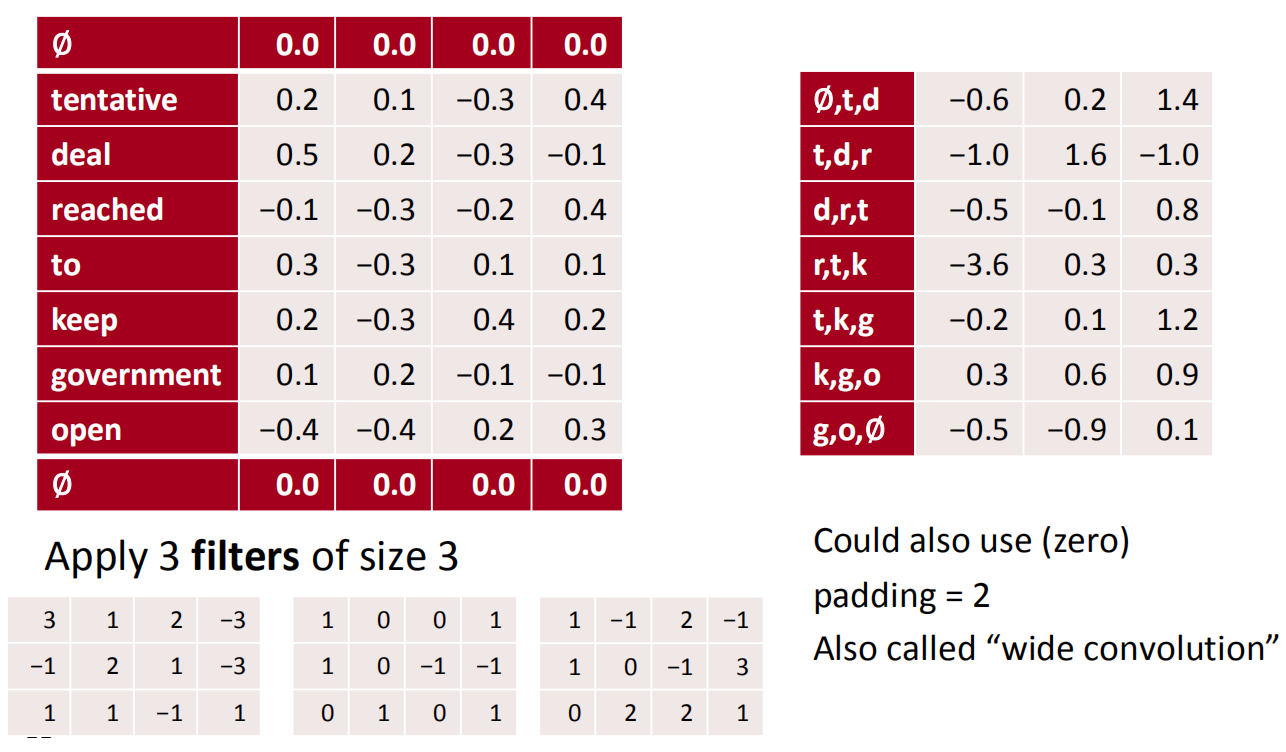
conv1d, padded with max pooling over time
接下来就是进行pooling操作,对于上面的3通道卷积核得出的结果进行最大值池化之后的结果如下:
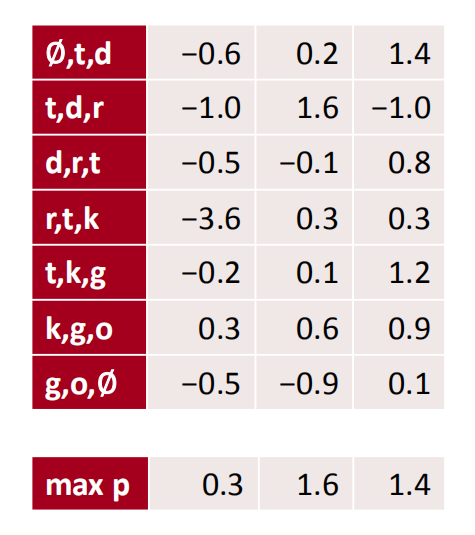
筛选出每个通道的最大值。
conv1d, padded with avepooling over time
对于上面的3通道卷积核得出的结果进行平均值池化之后的结果如下:
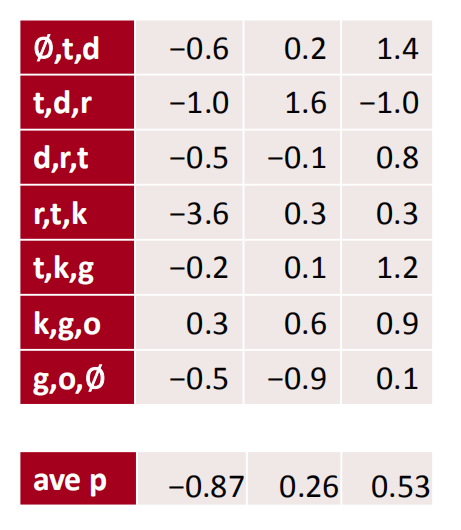
求一下每个通道的平均值。
Other less useful notions: stride = 2
如果卷积核的步长为2,即stride=2,结果如下:
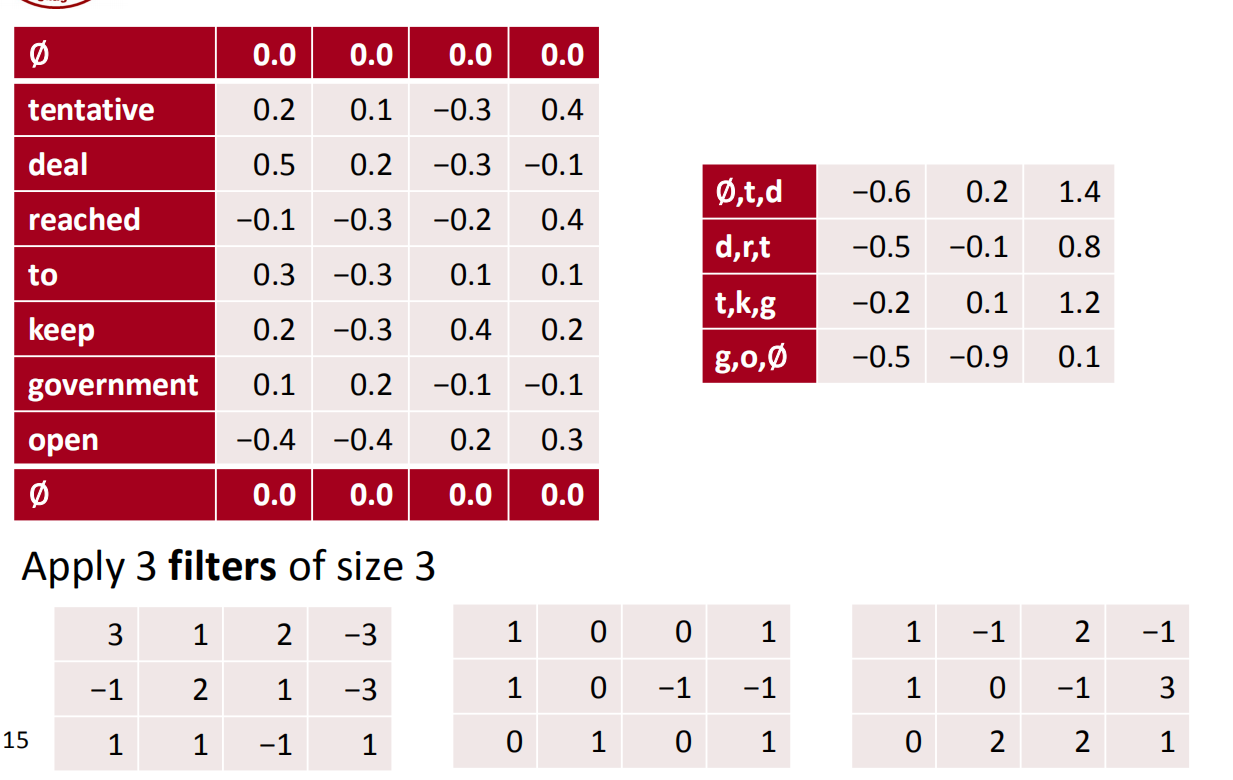
先求∅,tentative,deal(∅,t,d),接下来跨越一个单词求deal,reached,to(d,r,t)。
Single Layer CNN for Sentence Classification
课程里面给了一个CNN在NLP的一个经典模型,TextCNN,并阐述了它进行电影评论数据集的情感分类过程。
它使用了多个不同size的卷积核提取句子里的信息,更好的捕获句子里面的局部相关性。
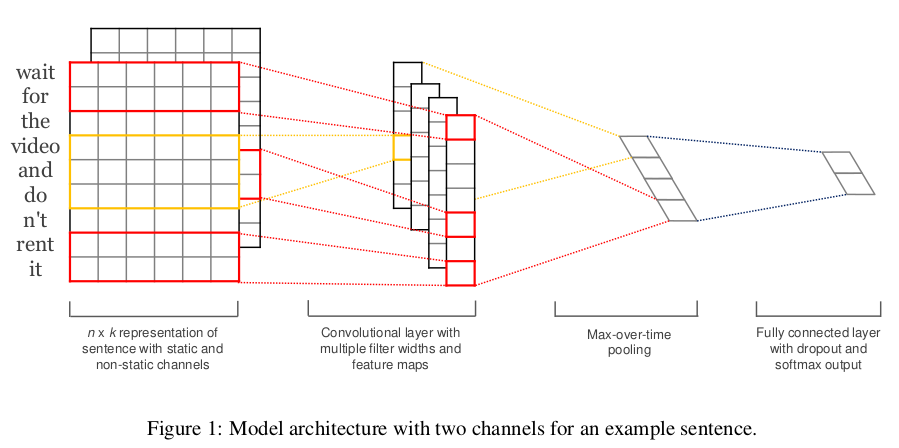
上图是宏观上的模型原理图,其中的操作可以看下文章前面的内容。
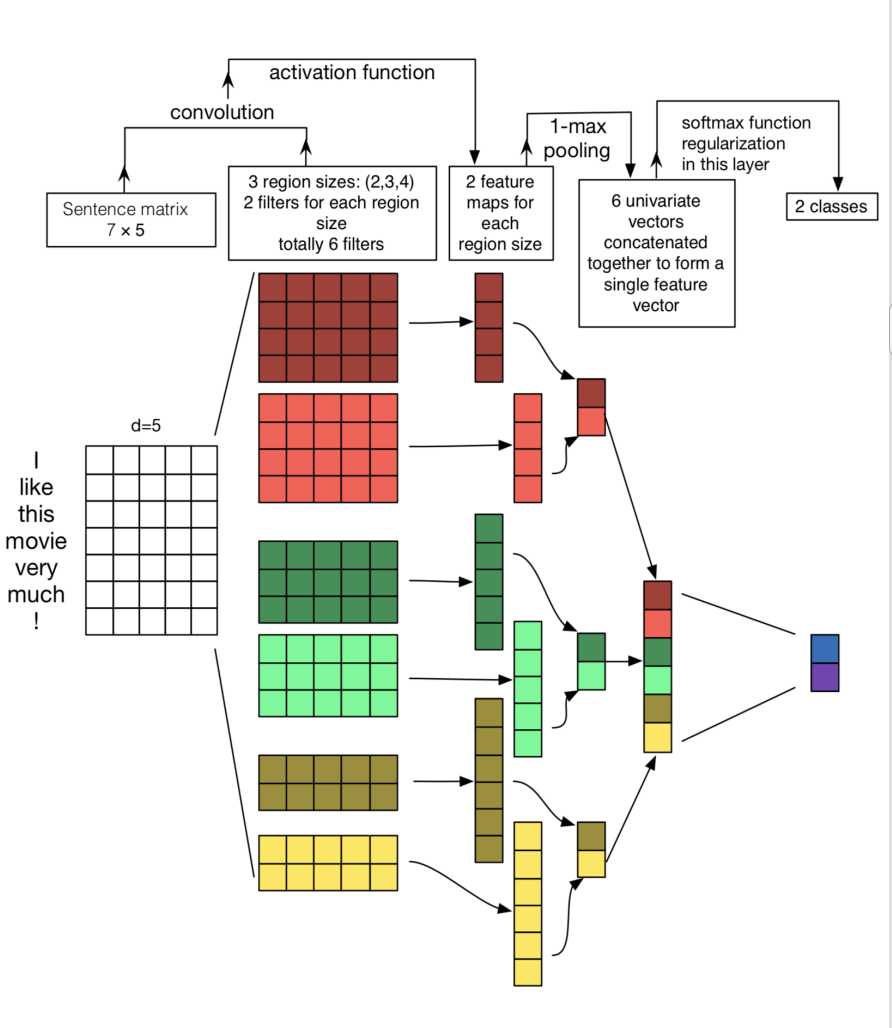
最左边是一个7行5列的矩阵,它是句子I like this movie very much !的embedding(可以来自于word2vec也可以是预训练模型输出的静态词向量,也可以是预训练模型经过fine-tunning出来的词向量),每一行都是对应的词向量,向量维度为5。接下来,把它经过size分别为2,3和5的卷积核,并且对应两个通道,总共就有6个卷积核。接下来进行max pooling,不同长度的句子经过池化之后得到了等长的向量表征。最后接一层全连接的softmax层,输出每个类别的概率。
Model comparison: Our growing toolkit
目前已经学到的NLP工具箱:
- 词袋模型:对于一个句子,简单的把所有词的词向量进行平均,也能取得不错的baseline效果
- 基于滑动窗口的模型:对于POS、NER等不需要很长的上下文信息的问题来说,效果不错
- CNN:对分类问题效果很好,容易在GPU上并行,所以效率很高
- RNN:对于NLP问题来说,符合认知,对分类问题效果不是很好(如果只用最后一个隐状态的话),加上Attention性能提升明显,特别适合序列标注、语言模型等序列问题
Batch Normalization(BatchNorm)
Batch Normalization是一个在神经网络训练中很重要的手段,BN的主要思想就是:在每一层的每一批数据上进行归一化。我们可能会对输入数据进行归一化,但是经过该网络层的作用后,我们的数据已经不再是归一化的了。随着这种情况的发展,数据的偏差越来越大,我的反向传播需要考虑到这些大的偏差,这就迫使我们只能使用较小的学习率来防止梯度消失或者梯度爆炸。
BN的具体做法就是对每一小批数据,在批这个方向上做归一化。如下图所示:
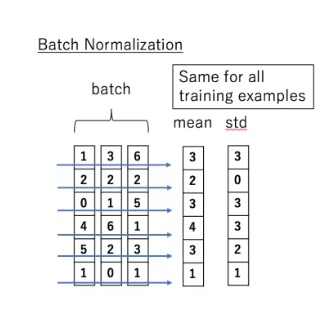
可以看到,右半边求均值是沿着数据 batch_size的方向进行的,其计算公式如下: