
Motivation: Question answering
问答系统(Question Answering, QA)是指对检索到的文档进行阅读理解,抽取出能回答问题的答案
Stanford Question Answering Dataset(SQuAD)
2015~2016年,几个大规模QA标注数据集的发表,极大的推动了这个领域的发展。这其中比较有名的数据集是斯坦福大学发布的Stanford Question Answering Dataset(SQuAD)。

- 文章是来自维基百科的一段文本,系统需要回答问题,在文章中找出答案
- 答案直接直接来自于文章,也就是提取式问答(给出答案所在的收尾位置之间的单词序列)
- SQuAD由100k个examples构造而成

为了增加数据集的难度,斯坦福后续推出升级版本SQuAD2.0数据集中增加了没有答案的问题,可以理解为假问题,对系统造成干扰。此时就要求系统判断这个问题能否从文章描述中获得答案,如果没有答案的话,就不输出任何回答<No Answer>。
Stanford Attentive Reader
这是一个基于SQuAD数据集开发的QA架构,它比较轻量级,性能一般,常被用作解决QA问题的一个baseline模型。
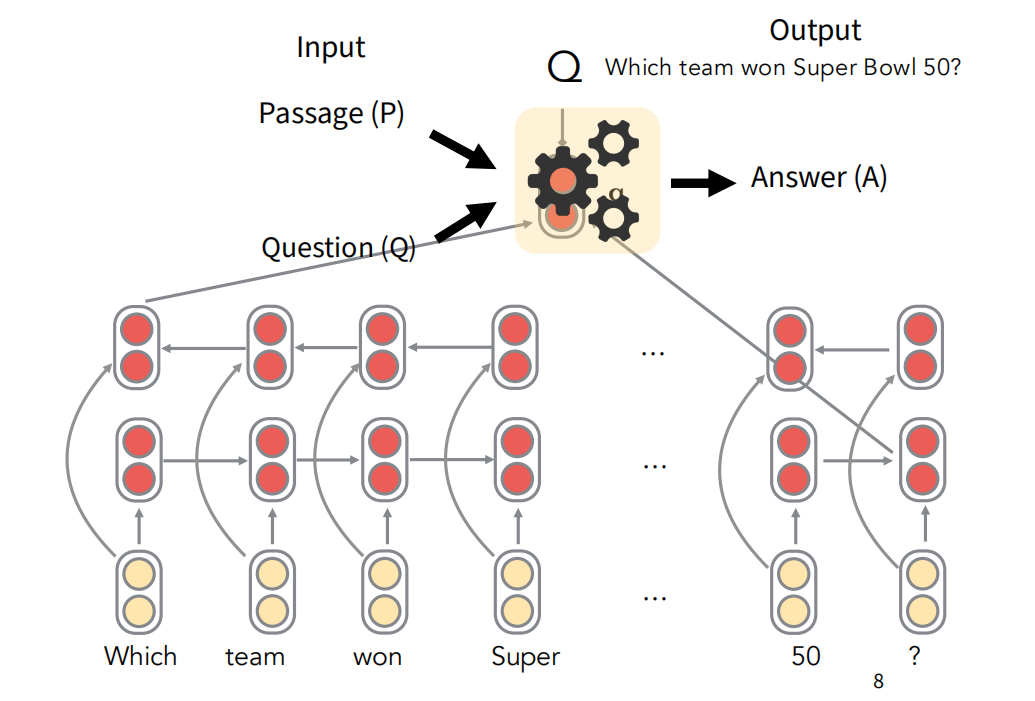
对问题Q的每个词进行embedding得到词向量,然后使用双向LSTM去抽取句子的特征,把正向和反向的LSTM的最后一个隐状态拼接起来,作为对整个句子的表征$q$。
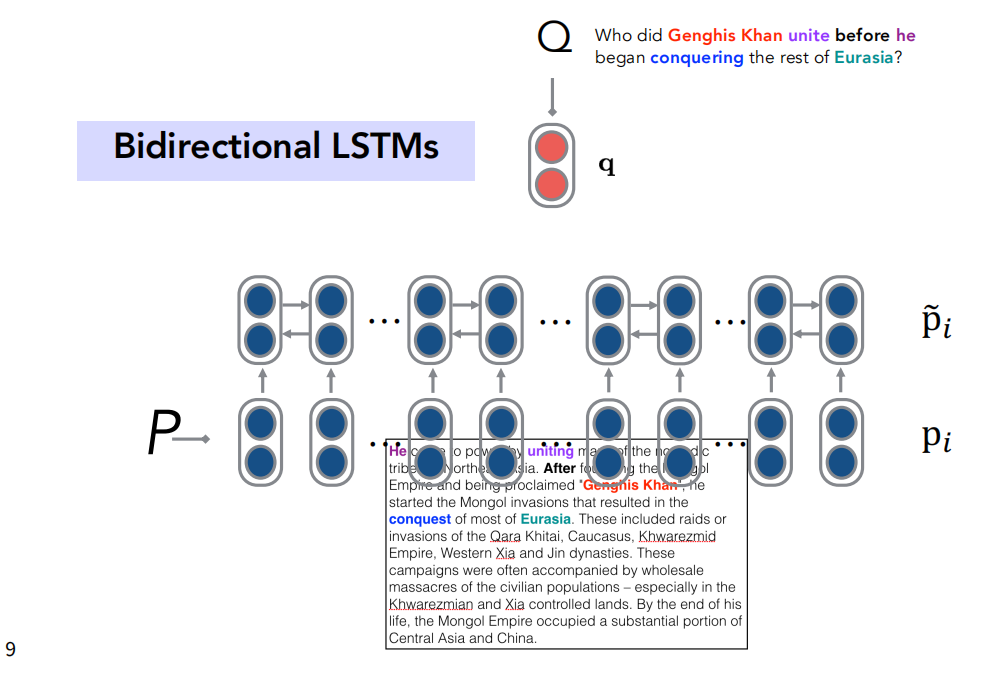
SQuAD的问题答案在P中,模型只需要找到对应答案在P中的位置就行(span)。我们对P也使用和Q一样的处理方式得到P中每个词的表征向量$\tilde{p}_i$,然后使用两次注意力机制,用$q$查询集合$p=[\tilde{p}_1,\tilde{p}_2,…,\tilde{p}_n]$,得到答案在P中的起始位置$\alpha_i$和结束位置$\tilde{\alpha}_i’$。
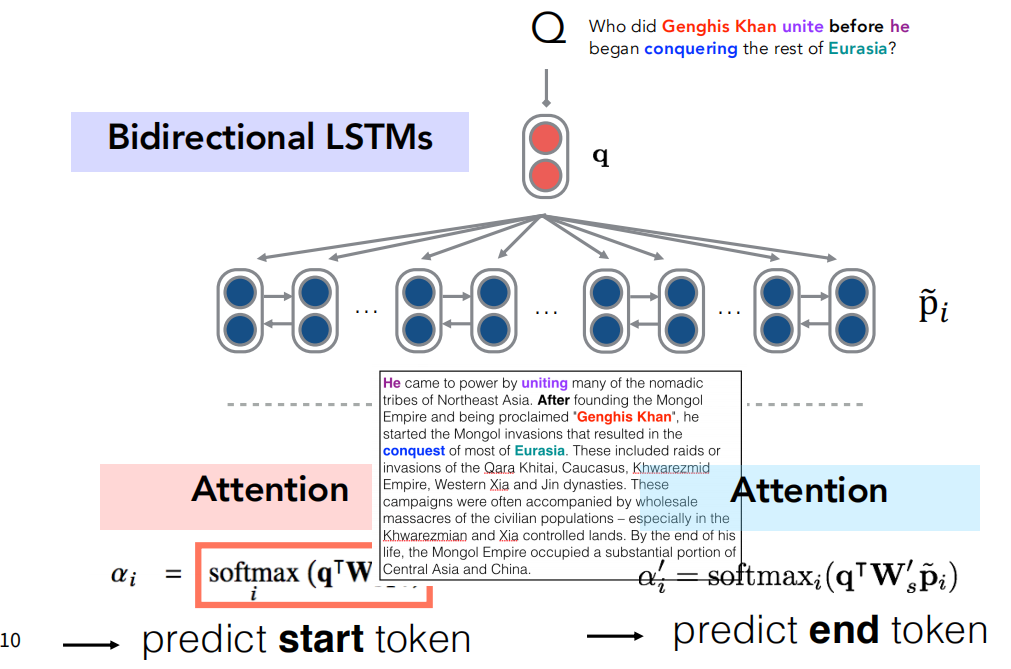
因为$q$和$\tilde{p}_i$的维度不一样无法直接通过点积计算注意力得分,所以引入参数$W$
Stanford Attentive Reader++
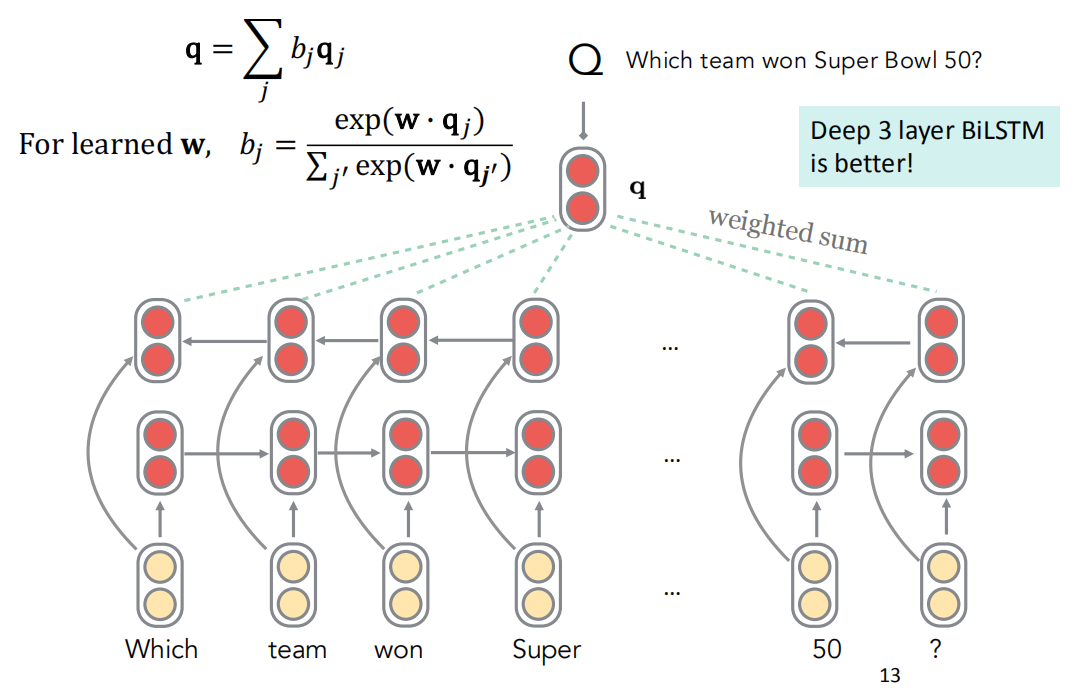
相对于上一个模型,这个模型做了两个改变,对于问题Q的表征,$q$不仅包含了双向LSTM首尾的两个输出的隐状态,它使用了$w$这个可学习的变量描述整个问题所有隐状态的加权平均,并且加深网络层数到3层;对于P部分的表征,原来的输入仅仅包含词向量,它引进了更多的语言特征,如POS标签、NER标签、词频等。这个++版本的改进相对于前一个有不少的提升。
BiDAF: Bi-Directional Attention Flow for Machine Comprehension
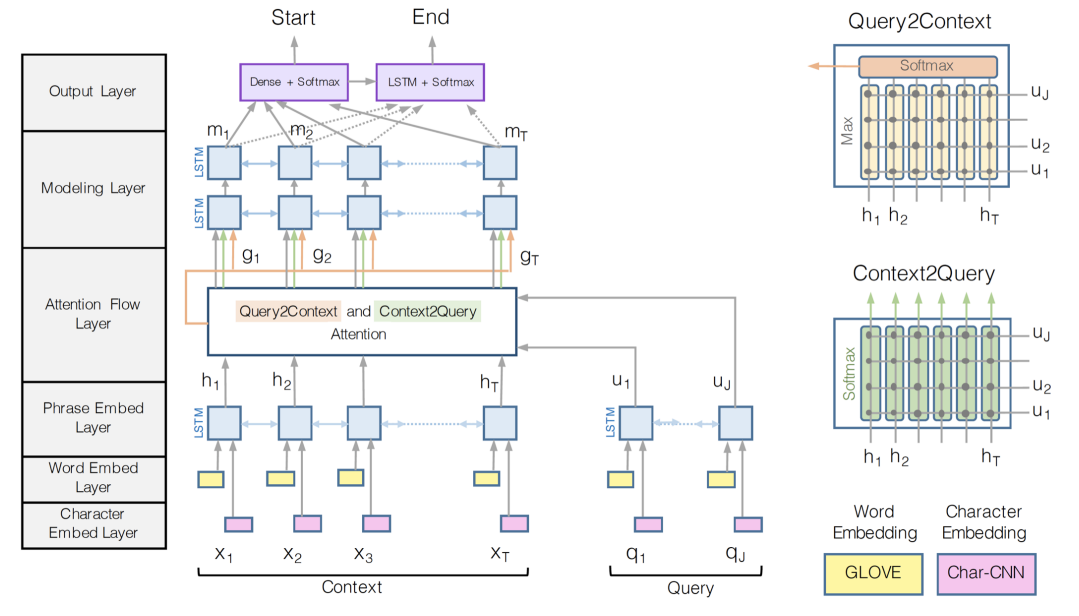
这个QA模型对于问题Q和描述P的建模除了引入它们的词向量,还引入了字符级别的特征,并且,在做attention时,做了双向的attention,即除了问题对描述的注意力,还有描述对问题的注意力。
Recent, more advanced architectures
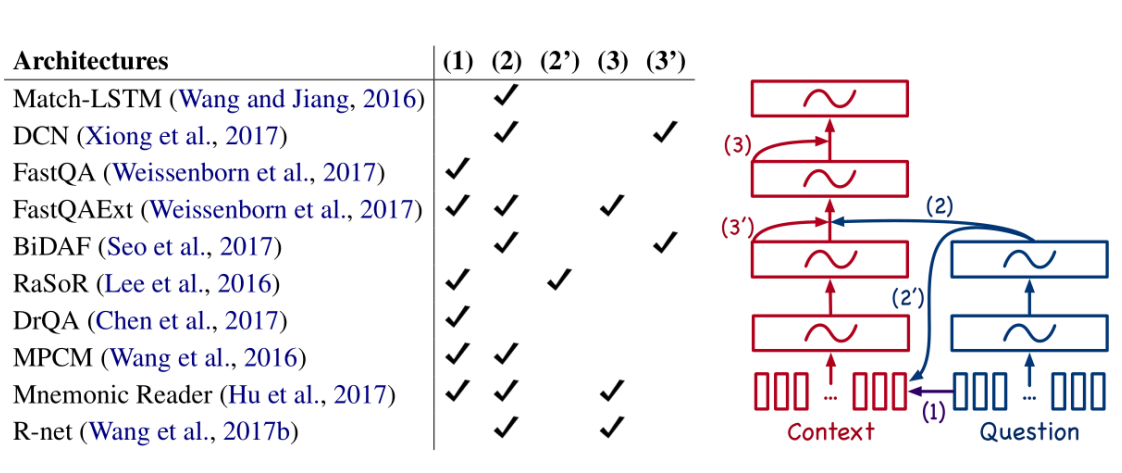
之后的研究工作,大家发现,对QA系统中attention设计的改进可以获得很多的提升。
Dynamic CoattentionNetworks for Question Answering
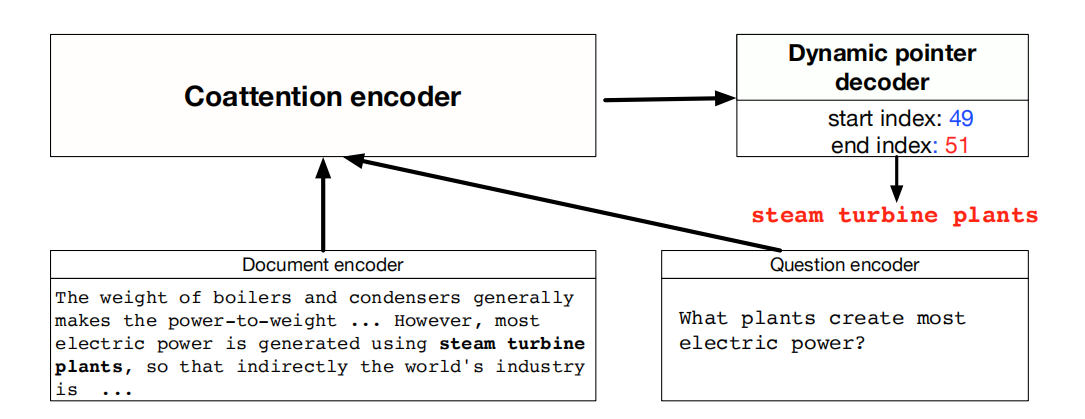
这篇文章认为一个全面的QA模型需要更多的相互依赖,也就意味着更多更复杂的attention需要被引入。
Coattention Encoder
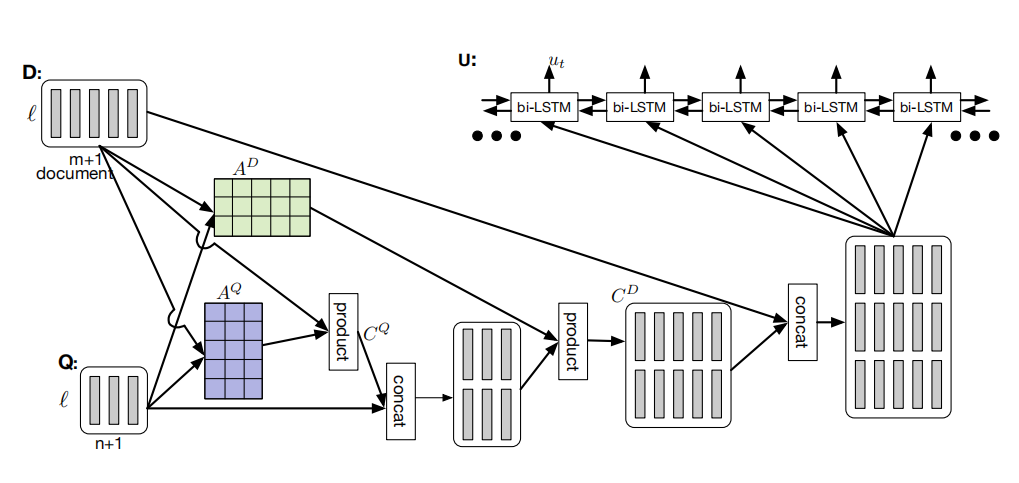
Coattention Encoder包括两级注意力的计算,首先对D和Q之间产生一个互注意力层(Coattention layer),然后对这个互注意力层和问题Q之间再次进行attention。
FusionNet
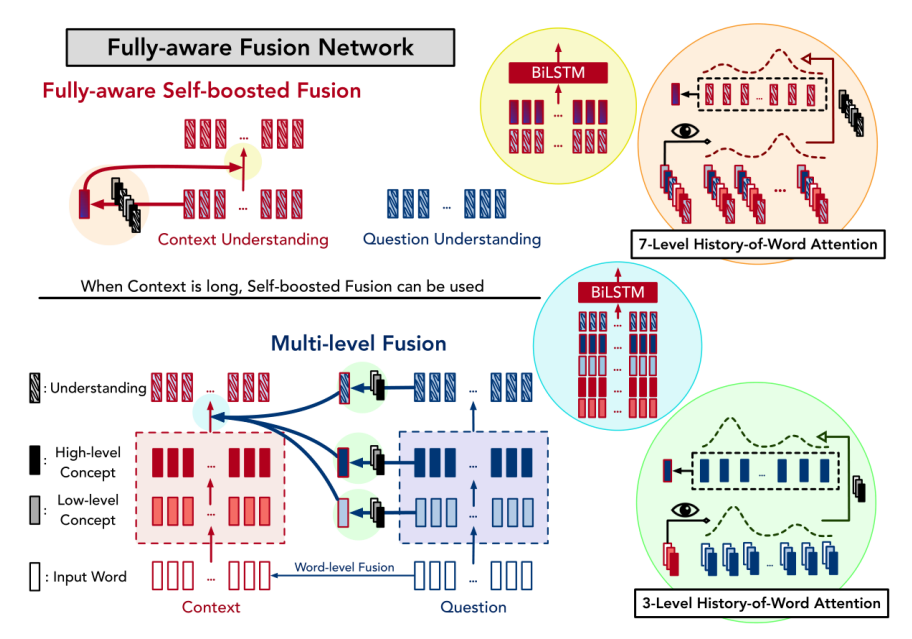
多层感知机(Multi-layer Perceptron,MLP),是模型结构相对简单但在工业界运用比较广泛的深度模型。MLP模型是包含多个全连接隐藏层的前向反馈模型,它计算注意力分数一种方式是(维度不一样,引入$W$参数):
它改成了双线性形式:
这样的attention消耗较少的空间,且非线性。
Multi-level inter-attention
这部分引入了self-attention在上下文中做更多的inter-attention。现如今QA问题的比较好的性能都是由Bert给出,由此引进了预训练模型。
ELMo and BERT preview
此部分内容之前已经在彻底搞懂BERT文章中学习过
补充:如何使用Bert做基于阅读理解的信息抽取
就像前面介绍的,在BERT出来之前,机器阅读理解主要用LSTM等特征抽取分别对Paragraph(P)和Question(Q)进行表征,抽取特征。再将二者的特征进行一些运算,得到相应的输出表征。
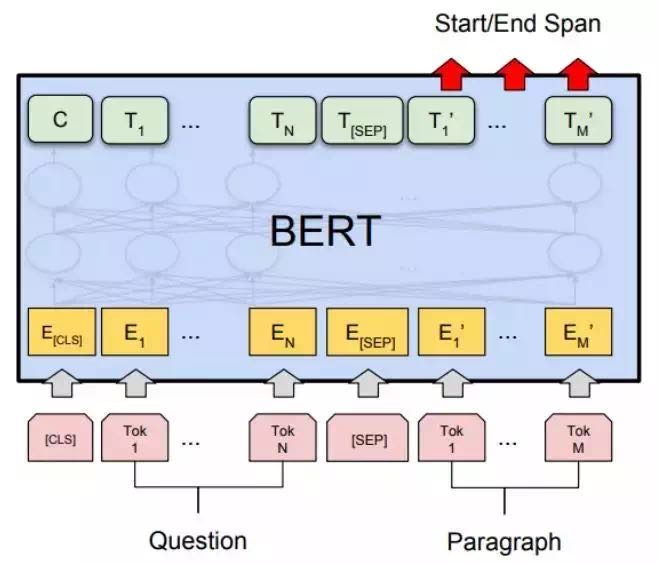
如上图所示,展示了如何用Bert来做信息抽取任务的结构图,注意以下几点即可:
- 将Question和Paragraph分别作为BERT的text1和text2输入。
- start/end span在Paragraph对应的输出位置表示。
通常输出会通过2个dense网络,接到start输出和end输出序列。
假设Paragraph为“周杰伦出生于台湾”,Question为“周杰伦出生于哪里?”,则laebl为:start[0,0,0,0,0,1,0],end[0,0,0,0,0,0,1]。
将上述start输出和end输出序列接一个sigmod层,然后用binary_crossentropy函数即可进行训练。
如果想要输出一个Answer是否正确的概率,可用将[CLS]的输出表征利用起来。