
前言
对于句法结构(syntactic structure)分析,主要有两种方式:Constituency Parsing与Dependency Parsing
Constituency Parsing
Constituency Parsing主要用phrase structure grammer即短语语法来不断的将词语整理成嵌套的组成成分,又被称为context-free grammers,简写做CFG
其主要步骤是先对每个词做词性分析part of speech, 简称POS,然后再将其组成短语,再将短语不断递归构成更大的短语

例如,对于 the cuddly cat by the door, 先做POS分析,the是限定词,用Det(Determiner)表示,cuddly是形容词,用Adj(Adjective)代表,cat和door是名词,用N(Noun)表示, by是介词,用P(Preposition)表示。
然后the cuddly cat构成名词短语NP(Noun Phrase),这里由Det(the)+Adj(cuddly)+N(cat)构成,by the door构成介词短语PP(Preposition Phrase), 这里由P(by)+NP(the door)构成。
最后,整个短语the cuddly cat by the door 是NP,由NP(the cuddly cat)+ PP(by the door)构成。
Dependency Parsing
Dependency Structure展示了词语之前的依赖关系,通常用箭头表示其依存关系,有时也会在箭头上标出其具体的语法关系,如是主语还是宾语关系等。
Dependency Structure有两种表现形式,一种是直接在句子上标出依存关系箭头及语法关系,如 :
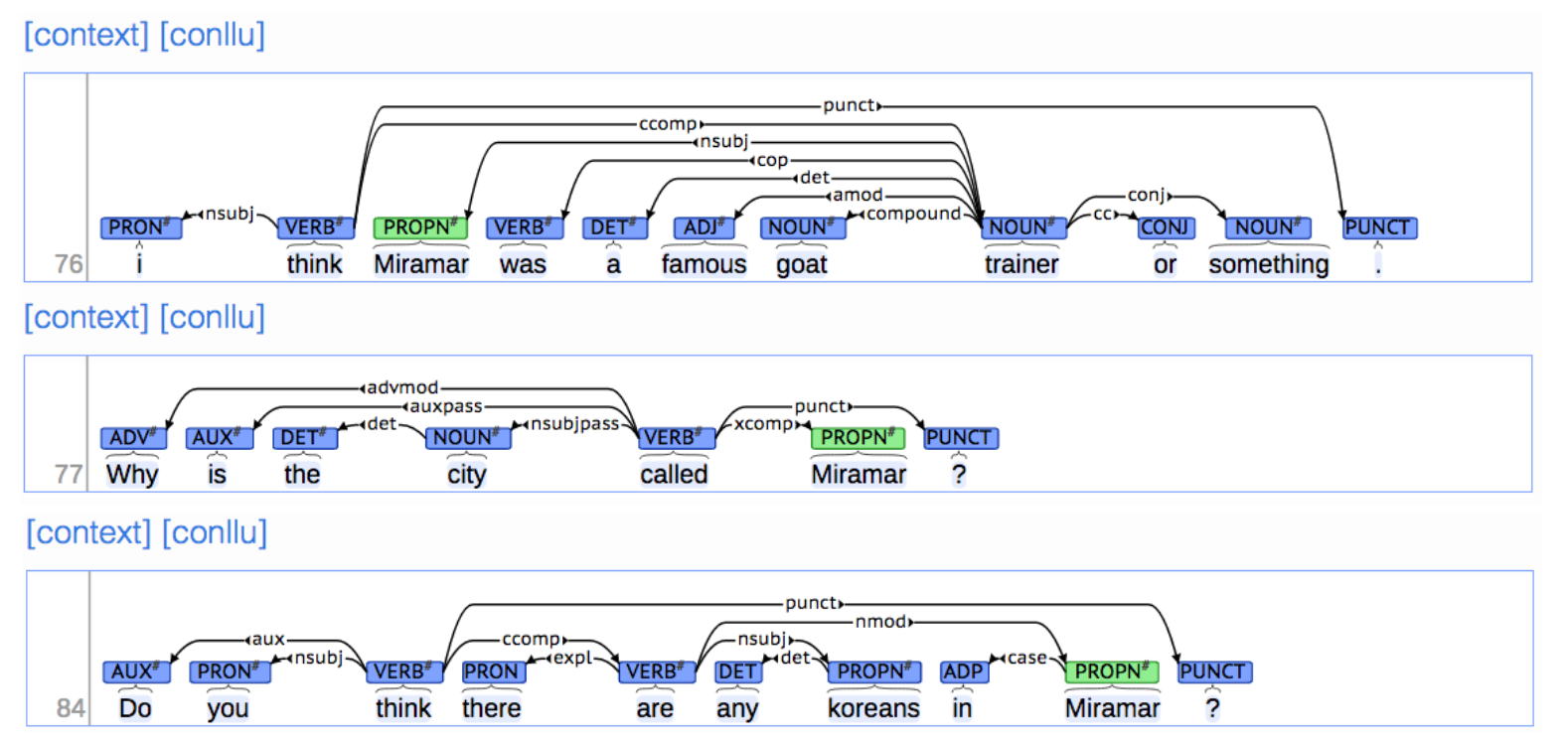
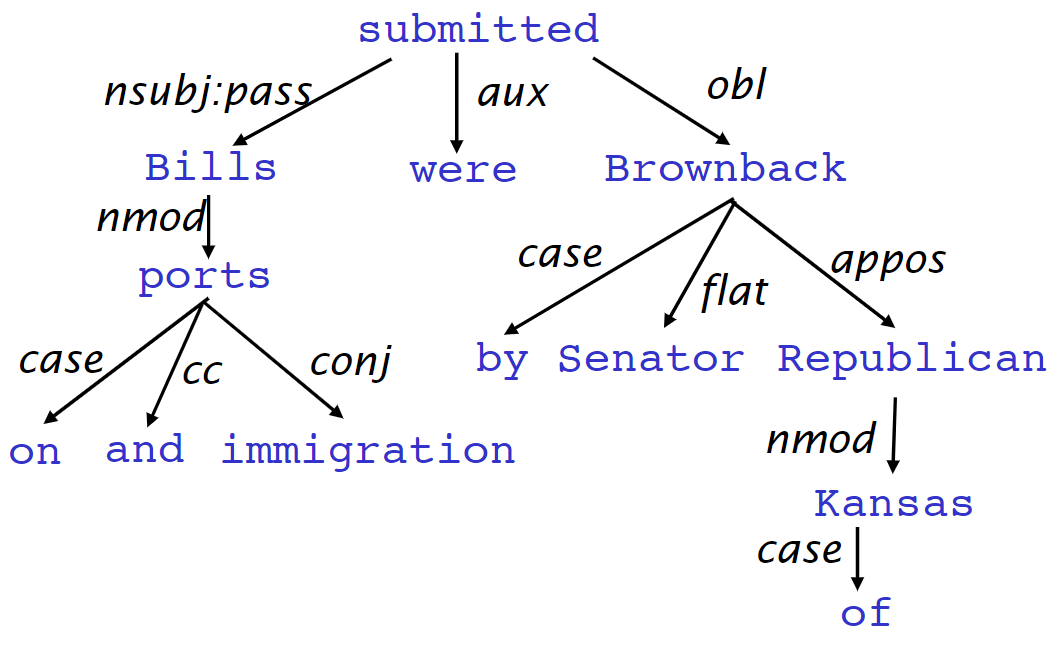
另一种是将其做成树状机构(Dependency Tree Graph)
Bills on ports and immigration were submitted by Senator Brownback, Republican of Kansas
堪萨斯州共和党参议员布朗巴克(Brownback)提交了有关港口和移民的法案
Dependency Parsing可以看做是给定输入句子$S=w_0w_1…w_n$(其中$w_0$常常是fake ROOT,使得句子中每一个词都依赖于另一个节点)构建对应的Dependency Tree Graph的任务。而这个树如何构建呢?一个有效的方法是Transition-based Dependency Parsing
Transition-based Dependency Parsing
Transition-based Dependency Parsing可以看做是状态机,对于$S=w_0w_1…w_n$,其状态由三部分构成$(\sigma,\beta,A)$
$\sigma$是$S$中若干$w_i$构成的堆(stack)
$\beta$是$S$中若干$w_i$构成的缓冲(buffer)
$A$是$w_i$之间的关系依存弧构成的集合,每一条边的形式是$(w_i,r,w_j)$,其中$r$描述了节点的依存关系(如动宾关系等)
初始状态时,$\sigma$仅包含ROOT$w_0$,$\beta$包含了所有的单词$w_1…w_n$,而$A$是空集$\varnothing$。最终的目标是$\sigma$包含ROOTT$w_0$,$\beta$清空,而$A$包含了所有关系, $A$就是我们想要的描述Dependency的结果
其含义是对于$S$中所有的单词都找到了相互的关系
状态之间的转移有三类 :
- 移除在缓冲区的第一个单词,然后将其放在堆的顶部(前提条件:缓冲区不能为空)。
- LEFT-ARC:向依存弧集合$A$中加入一个依存弧$(w_j,r,w_i)$,其中$w_i$是堆顶的第二个单词,$w_j$堆顶部的单词。从堆栈中移除$w_i$。
- RIGHT-ARC:向依存弧集合$A$中加入一个依存弧$(w_i,r,w_j),其中$w_i$是堆顶的第二个单词,$w_j$堆顶部的单词。从堆栈中移除$w_j$。
我们不断的进行上述三类操作,直到从初始态达到最终态。
在每个状态下如何选择哪种操作呢?
- 当我们考虑到LEFT-ARC与RIGHT-ARC各有|R|(|R|为r的类的个数)种类别,我们可以将其看做是类别数为2|R|+1的分类问题。
- 每一个stack+buffer的状态相当于输入,3种操作相当于输出,把这个问题建模成分类问题。于是Nivre等人对每一个stack+buffer的状态,人工抽取出很多的特征,然后使用logistic或者svm进行分类。但是,当时的特征设计都是0/1状态的,特征向量很稀疏;特征又多,抽取特征很花时间。
Evaluation
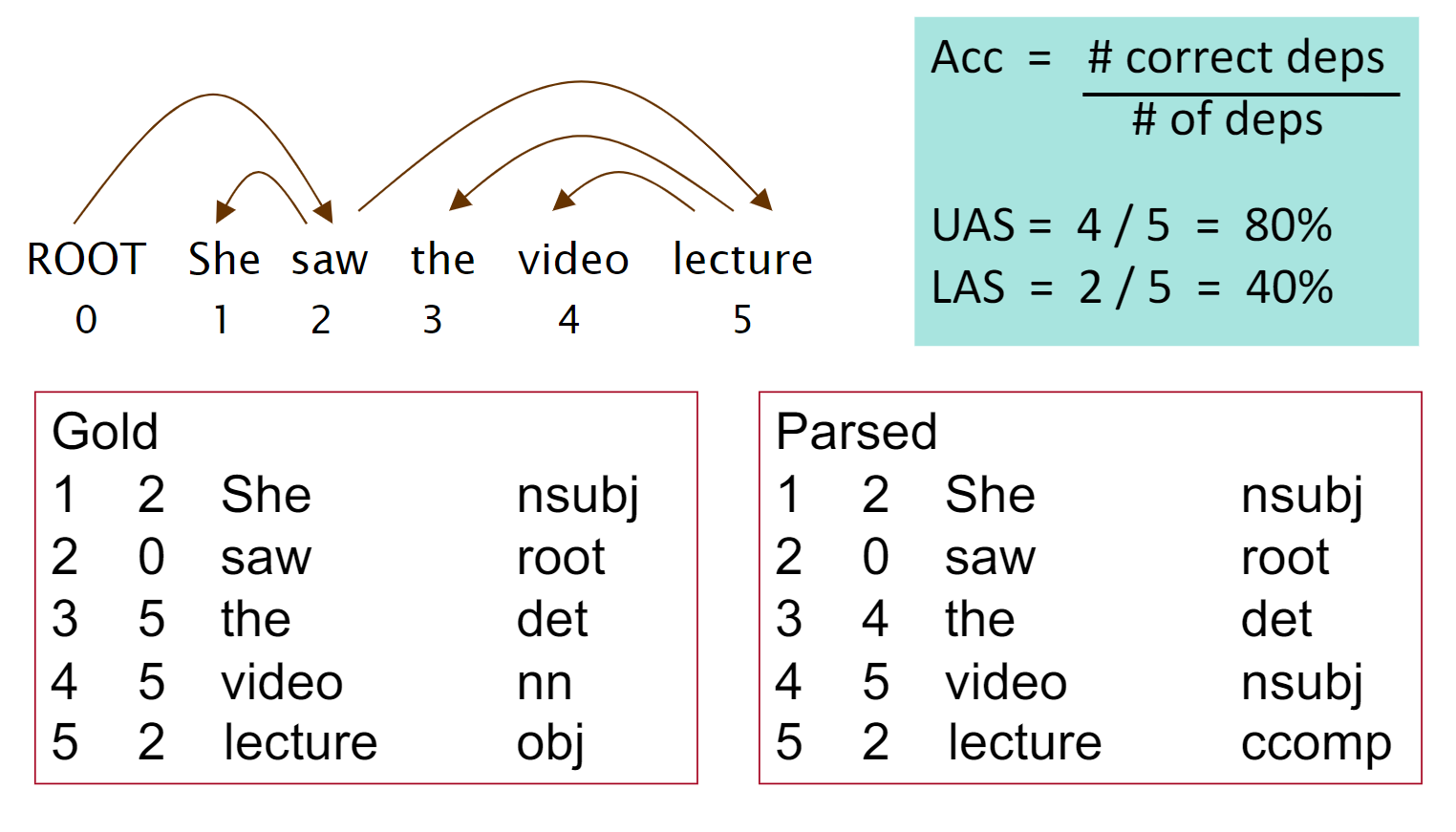
当我们有了Dependency Parsing的模型后,我们如何对其准确性进行评估呢?
我们有两个metric,一个是LAS(labeled attachment score)即只有arc的箭头方向以及语法关系均正确时才算正确,以及UAS(unlabeled attachment score)即只要arc的箭头方向正确即可。
Neural Dependency Parsing
传统的Transition-based Dependency Parsing对特征工程要求较高,我们可以用神经网络来减少人力劳动
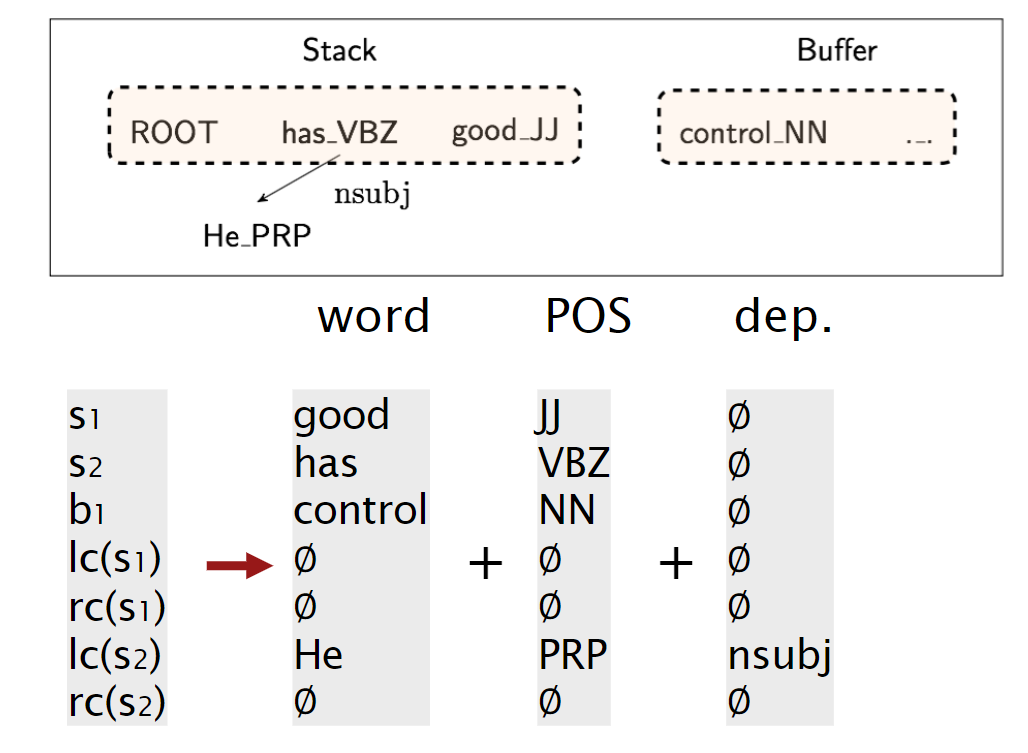
对于Neural Dependency Parser,其输入特征通常包含三种:
- stack和buffer中的单词及其dependent word。
- 单词的Part-of-Speech tag。
- 描述语法关系的arc label。
当神经网络火了之后,人们自然想到了用神经网络替代logistic或svm,提出了新的句法分析器。他们对于每一个stack+buffer的状态,抽取出words、POS tags和arc labels三种不同类型的特征,都用词向量来表示。然后输入只有一个隐层的全连接网络,效果立马超过了之前所有人工设计的特征和方法。基于这个工作,后续又有很多改进版本。
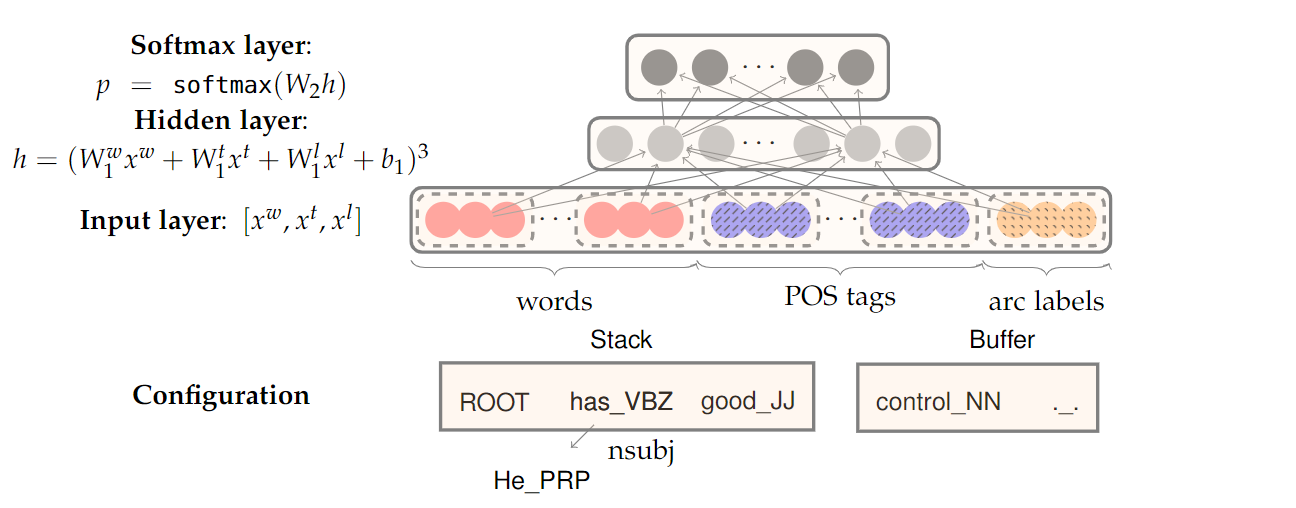
利用这样简单的前置神经网络,我们就可以减少特征工程并提高准确度,当然,RNN模型也可以应用到Dependency Parsing任务中。